
The wrong question is "which Claude model is the best one". The right question is narrower and more useful: which capability tier does this specific task need, given its consequence, its ambiguity, its sensitivity and the review it will trigger. Get that habit right and the lineup can change underneath you without breaking your workflow. Get it wrong and you will overpay for trivial work, under-resource the work that can harm someone, and tie your governance to a marketing label that may not exist next quarter.
This is a learning-hub piece, so it is built to teach a method rather than to sell a model. The method has one rule that runs through everything below: route the task before you write the prompt. The prompt inherits the risk of the task, so the routing decision has to come first.
General guidance and education only. This is not legal, compliance, privacy or professional advice. Verify any approach, and any current model availability, with the relevant people in your own organisation before you act on it.
A cleaner way to frame the whole approach: treat the model as a structure engine, a critique partner and a drafting accelerator, and keep the source evidence, the professional judgement and the accountable sign-off with named people. Routing is how you decide how much of that first job the task can safely hand over. Over-routing wastes money and hides weak workflow design. Under-routing puts a fast model in front of a decision it was never built to make.
Should you route by capability tier, not by model name?
The single most durable idea in this article is that you should route by capability tier, not by model name. Anthropic publishes its current lineup with capability descriptions, model IDs and pricing, and that lineup is revised regularly [1]. If your internal guidance says "use Sonnet for that", it dates the moment a new model ships or an old one is retired. If it says "use the reasoning tier for that", it survives.
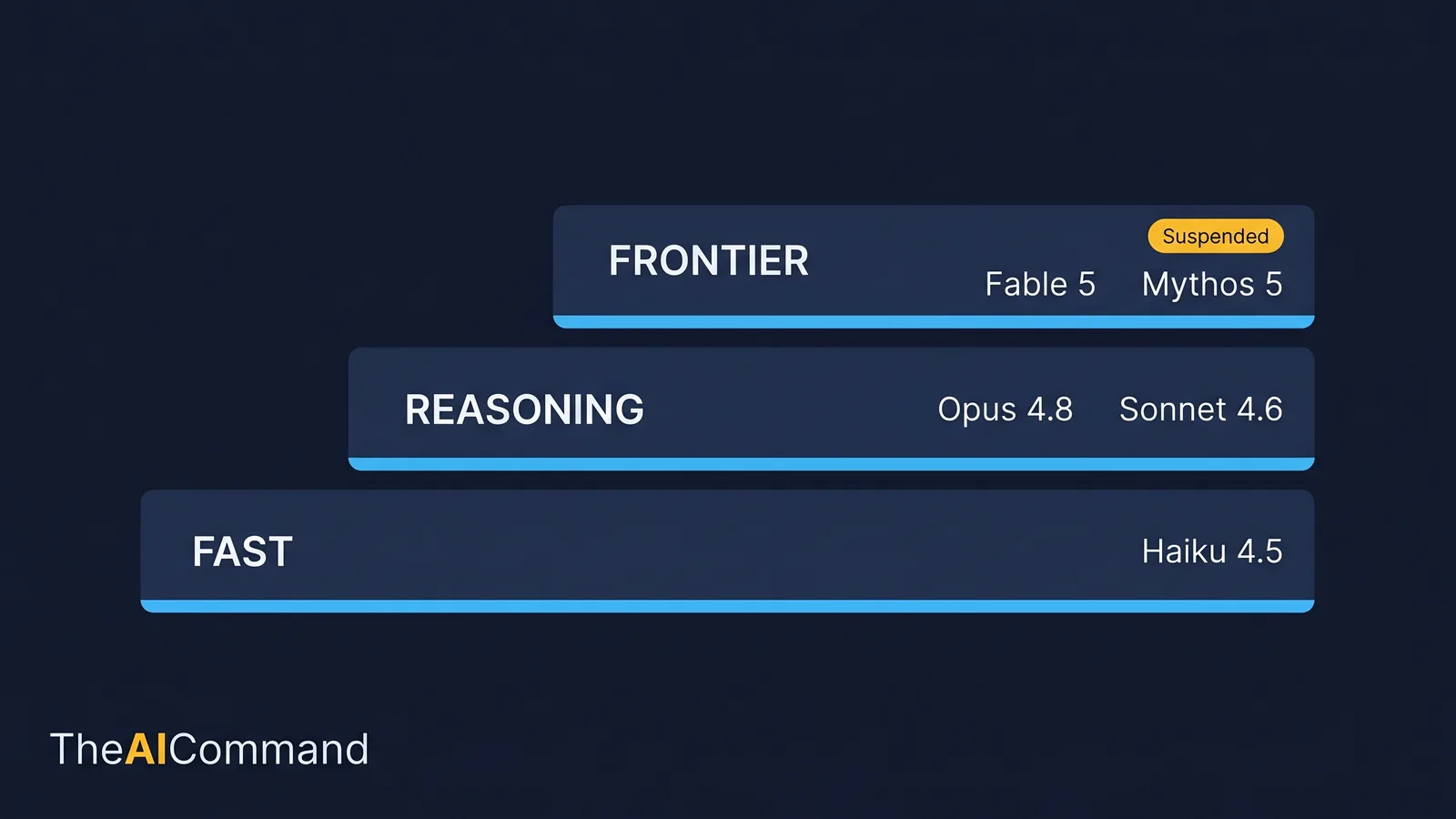
Three tiers cover almost all professional work.
- Fast tier. Cheap, low latency, near-frontier on simple work. Good for high-volume, low-ambiguity tasks where a human can inspect the output at a glance. As at 14 June 2026 this tier is Claude Haiku 4.5 [1].
- Reasoning tier. Strong analysis, structured drafting, nuanced tone and exception handling. Good for work that mixes judgement with structure. As at 14 June 2026 this tier is Claude Opus 4.8 and Claude Sonnet 4.6 [1].
- Frontier tier. The most capable widely released models, for the most demanding reasoning and long-horizon agentic work. As at 14 June 2026 this tier is Claude Fable 5 and Claude Mythos 5, and it is the live example of why you should never bind your method to a name [1][2].
Why the frontier example matters
Anthropic released Claude Fable 5 and Claude Mythos 5 on 9 June 2026 [1][3]. Three days later, on 12 June 2026, it disabled access to both for all customers to comply with a US government export-control directive [2]. The directive, reported as issued through the Commerce Department's Bureau of Industry and Security under Secretary Howard Lutnick, suspends access by any foreign national, inside or outside the United States, including Anthropic's own foreign-national staff [4][5]. The reported trigger was a narrow jailbreak that, in Anthropic's description, "essentially consists of asking the model to read a specific codebase" [2]. Because Anthropic cannot filter foreign nationals from United States users in real time, it took both models down for everyone and said it is "working to restore access as soon as possible", with no restoration date given [2].
For an Australian organisation the practical effect is blunt. As at 14 June 2026, Australian users are foreign nationals for the purpose of that directive, so Fable 5 and Mythos 5 are not available to them. Every other Claude model is unaffected, so Opus 4.8 is the highest currently-available tier and the rest of the lineup is online [1][2]. This status is dated and may change; confirm it against the primary sources before you rely on it.
That is the argument for routing by tier in one paragraph. A team that wrote "use Fable 5 for board memos" into its AI policy on 11 June had a broken policy by 12 June. A team that wrote "route board memos to the highest available reasoning or frontier tier, with risk-owner sign-off" simply re-pointed to Opus 4.8 and kept working. The route is the governance object. The model name is a perishable input.
Evergreen principle: route by capability, not by model name. Model lineups change for commercial, technical and, as Fable 5 showed, geopolitical reasons. If your routing logic is written in terms of fast, reasoning and frontier tiers, plus the review each tier demands, it keeps working when a model is added, retired or, in rare cases, taken offline by a government. Treat any specific model name as a dated example you maintain, not as the rule itself.
How do you score a task before routing it?
Tiers tell you the shelf. A four-dimension score tells you which shelf a given task belongs on. Score each task from one to five on four dimensions, then let the highest-risk dimension pull the routing decision upward.
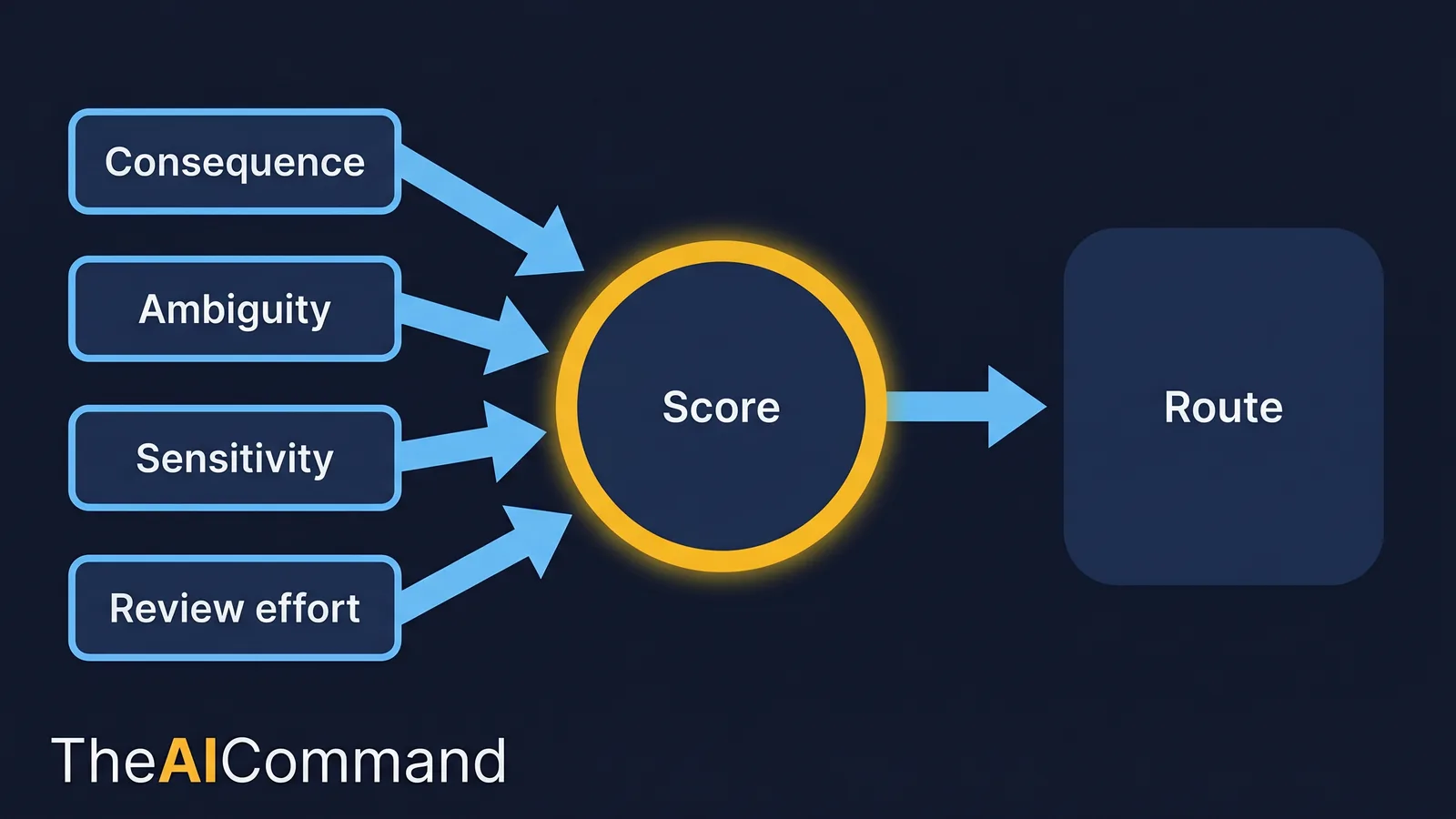
The four dimensions are deliberately plain so a non-technical manager can apply them.
How to read the scores:
- Low across all four (totals roughly 4 to 8). Route to the fast tier with a spot check. The output is easy to inspect and the cost of a miss is small.
- Medium, or a single high dimension (totals roughly 9 to 14). Route to the reasoning tier with structured review by the process or domain owner.
- High on consequence or ambiguity (totals roughly 15 and up). Route to the highest available reasoning or frontier tier, require expert review, and treat sign-off as a separate step.
- High on sensitivity at any total. Sensitivity is special. A high sensitivity score does not just push the tier up; it asks whether the task should go to a hosted model at all before de-identification, environment controls and permissions are confirmed, a call worked through in privacy-safe AI for regulated work. The right answer is sometimes "not yet".
The scoring is a conversation starter, not a formula. Its value is that it forces a shared judgement about the task before anyone opens a chat window, which is exactly the moment that risk is cheapest to manage.
A worked scoring example
Take one real task: drafting a one-page executive note that explains why the evidence for a material control is weaker than the control owner believes, without overstating the risk to the committee.
- Consequence of error: 5. A misjudged note can either alarm a committee unnecessarily or, worse, let a genuine control gap look settled.
- Ambiguity: 5. The whole task is judgement. Tone, proportionality and what the evidence is allowed to mean all sit in the grey.
- Sensitivity: 2. The source is internal control evidence, not personal or claim data, so it is sensitive but not acutely so.
- Review effort: 4. The errors that matter are subtle ones of emphasis and certainty, which only an experienced reviewer will catch.
Total of sixteen, with two dimensions maxed out. Route: highest available reasoning or frontier tier. As at 14 June 2026 that is Opus 4.8, because Fable 5 is suspended [1][2]. Review owner: the risk owner for that control, not the analyst who prompted the model. Mode: draft with the model, then run a separate critique pass, then human sign-off. The model accelerates the drafting and the challenge; a named person owns what the note is allowed to say.
Higher risk pulls work up the ladder
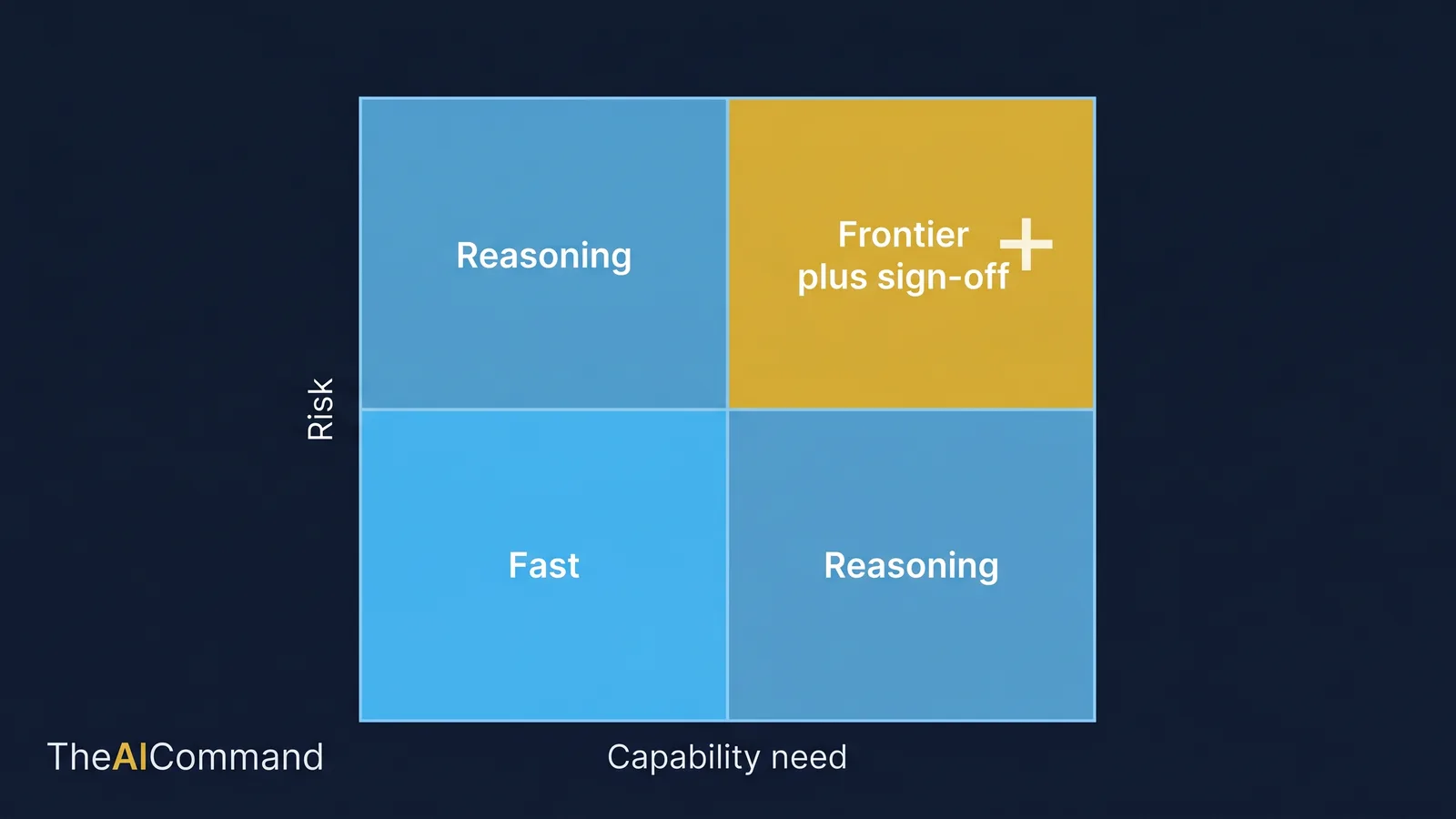
The scoring and the tiers meet on one picture. Plot ambiguity and consequence against capability, and the regulated zones become obvious. Low ambiguity and low consequence sit in the fast-and-spot-check corner. High ambiguity or high consequence pull the task up the capability ladder and into a stricter review lane. Sensitivity sits across the top of the whole picture as a gate, because no amount of capability fixes the wrong information being sent to a hosted model in the first place.
This is where model selection becomes a recognised governance control rather than a personal preference. The NIST AI Risk Management Framework is organised around four functions, Govern, Map, Measure and Manage, and routing touches all four: you govern by setting the routing policy, you map by classifying the task, you measure by logging error rates per route, and you manage by changing the route when the evidence says so [6]. ISO/IEC 42001:2023, the AI management system standard, expects organisations to manage AI risk through documented, auditable controls, and a written routing table with owners and review lanes is exactly that kind of control [7]. Framed this way, "which model did you use and why" stops being trivia and becomes an audit question with a documented answer.
Common tasks, mapped to a tier and a lane
The routing table below is the working artefact. It should fit on one page, name a tier rather than a single model so it survives lineup changes, and pair every route with a review owner. Model names appear only as dated examples.
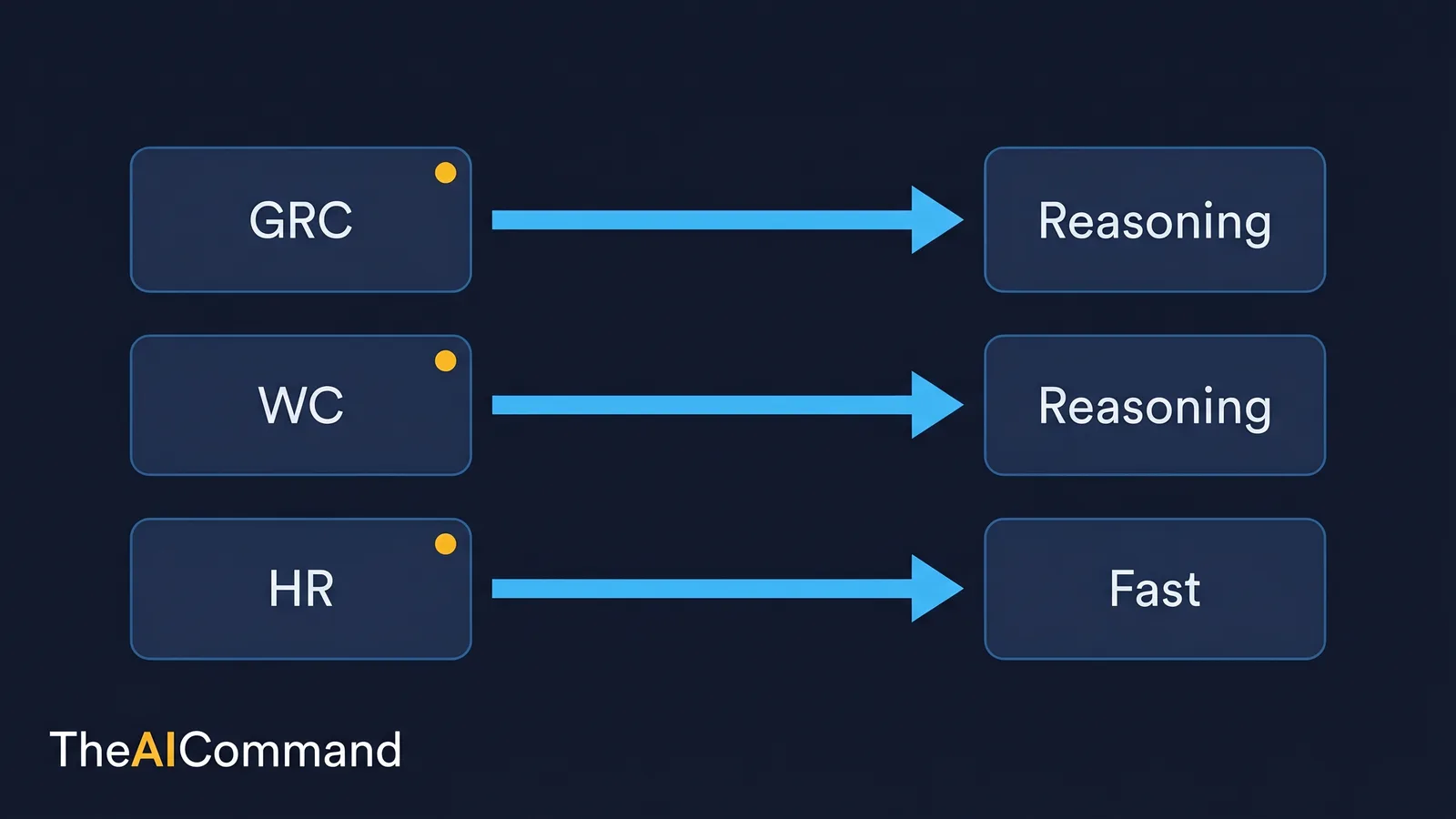
A note on the coding row. Claude Code is Anthropic's agentic coding tool, designed to work in a terminal against a real codebase, and it carries project context through a memory file so instructions, commands and constraints persist across sessions [8][9]. For regulated builds that means the model can be boxed in with documented constraints, but the dependency review, the offline check and the domain validation still belong to people. The same "route the task before you write the prompt" rule applies: a coding task that touches sensitive data is a high-sensitivity route, not a convenience.
Use the table as something a practitioner can copy into a planning document and adapt. If it needs a workshop to interpret, staff will quietly ignore it and route by habit instead.
The prompt stack, in routing order
The prompts below are staged on purpose. The first one narrows and routes the task. The middle ones produce the artefact under domain constraints. The last one challenges the result. That order reduces the chance of a fluent but unsafe output, because creation and verification are never the same step.
Route prompt
GRC prompt
WC prompt
HR prompt
Critique prompt
A discipline worth naming sits underneath all five: give the model the source boundary, tell it what not to infer, ask for uncertainty markers, and require a reference back to the evidence. When the source is incomplete, the correct output is a gap list, not a polished paragraph. This matters most in HR, GRC and WC work, where confident tone can make an unsupported claim look settled. Anthropic's own prompt-engineering guidance points the same way: be explicit about the task, the constraints and the output format rather than hoping the model infers them [10].
Where does model routing quietly fail?
Most AI failures in professional work are not caused by a missing magic prompt. They are caused by an unclear task boundary, weak source material, hidden assumptions, a single unreviewed pass and nowhere to store the lesson. Routing addresses the first and fourth of those directly, but it has its own failure modes.
- Using the strongest tier for everything. This wastes cost and, worse, hides poor workflow design behind raw capability. A reasoning-tier model used for a fast-tier task does not become safer; it becomes expensive and unexamined.
- Using a fast tier for high-ambiguity work. Speed does not substitute for judgement. A quick wrong answer on a disputed control is more dangerous than a slow right one, because it arrives with unearned confidence.
- Treating a model name as a control. The control is the route, the review lane and the named owner. The model name is an input that can change, as Fable 5 demonstrated within seventy-two hours of launch [2].
- Relying on a single pass. Regulated work needs creation, critique and sign-off as separate steps. The model that drafts an output should not be its only reviewer.
A useful governance test is to ask what the model is not allowed to do on a given task, and to make that answer visible in the route, the prompt and the review checklist. If the boundary only lives in one person's head, it will be missed under time pressure.
This routing logic is vendor-agnostic
Everything above is written in Claude terms because the lineup, pricing and the Fable 5 directive are concrete and verifiable. The method is not Claude-specific. Every major provider ships a fast tier, a reasoning tier and a frontier tier, and they all change their lineups regularly. Score the task on consequence, ambiguity, sensitivity and review effort; route to the lightest tier that does the work safely; pair the route with a named review owner; and log errors back to the route. That logic ports to any vendor unchanged. The same routing decision that cuts an AI bill also moves your data, so the cost and privacy trade-off travels with you across providers. The model names are dated examples you maintain in one place, so a lineup change is a single-line edit rather than a policy rewrite.
If your professional setup spans more than one assistant, the routing table belongs inside the wider operating system you build around your tools. The companion guide on a gold-standard ChatGPT and Codex setup covers how to structure projects, context boundaries and review loops across surfaces, and a routing table slots straight into it: see Gold Standard ChatGPT and Codex Setup. If you are still deciding which assistant fits which job, the companion guide to choosing between Claude, ChatGPT, Gemini and Copilot works one level up from tier routing.
Make the routing system stick
A routing table only earns its place if it learns. Stand up the smallest version that works, then improve it from evidence rather than opinion.
- Write a one-page task taxonomy for your GRC, WC and HR work.
- Score each task on consequence, ambiguity, sensitivity and review effort.
- Map each score band to a capability tier and a review lane, with model names shown only as dated examples.
- Build reusable prompt cards for routing, extraction, drafting, critique and sign-off.
- Keep a lightweight error log by route: missing caveat, invented source, weak structure, tone problem, privacy concern or misunderstood domain term.
- Review the log monthly. If one route keeps producing a class of error, change the tier, the prompt, the source requirement or the review step.
- Keep a dated current-models note so a lineup change, or a suspension like Fable 5, is a quick re-point rather than a redesign [1][2].
Name three hats to carry it: the domain owner confirms meaning, the AI workflow owner maintains prompts and routes, and the reviewer checks that outputs are grounded, proportionate and safe to use. Small teams can combine the hats, but they should still name them. Run the review with the artefact on screen, treat the model output like a useful but unchecked junior draft, and record each correction as a source issue, a prompt issue, a process issue or a judgement issue so the system improves and not just the one document.
The current model status as at 14 June 2026 is summarised below. Treat it as a snapshot that must be re-checked against the primary sources, because availability can change without notice.
What to do next
Pick one workflow, one artefact and one review loop. Score the task on the four dimensions before you write a single prompt. Route it to the lightest tier that does the job safely, using synthetic or low-sensitivity information where you can. Run the prompt stack in order: route, draft, critique. Capture what failed and turn the correction into a durable instruction, a prompt card or a routing-table change. Then repeat with a slightly harder task. That is how a governed routing capability compounds, and it is the opposite of pinning your workflow to a model name that may not survive the week.
Bottom line
Model selection is a governance decision, not a speed decision. Route each task to the lightest capability tier that does the work safely, score it on consequence, ambiguity, sensitivity and review effort, and pair every route with a named review owner. Write the table in terms of tiers so a lineup change, like the Fable 5 suspension, is a one-line re-point rather than a policy rewrite.
Do this Monday:
- Write a one-page task taxonomy for your GRC, WC and HR work.
- Score each task one to five on consequence, ambiguity, sensitivity and review effort.
- Map each score band to a capability tier and a named review lane, with model names shown only as dated examples.
- Run the prompt stack in order: route, draft, critique, then human sign-off.
- Keep a dated current-models note so a lineup change is a quick re-point, not a redesign.
This article is general guidance and education only. It is not legal, compliance, privacy, risk or other professional advice, and it does not establish that any model or tier meets a regulatory obligation. Model availability, pricing and access controls change, and the suspension of Claude Fable 5 and Mythos 5 described here is dated 14 June 2026 and may have changed since. NIST and ISO frameworks, your privacy obligations, and your own organisation's information security and AI policies take precedence. Confirm every regulatory point against the primary source, confirm current model availability with your provider, and confirm the approach with your accountable owners before relying on it in a regulated process.
References
- Anthropic, Models overview (Claude lineup, model IDs and pricing). https://platform.claude.com/docs/en/about-claude/models/overview
- Anthropic, Statement on the US government directive to suspend access to Fable 5 and Mythos 5. https://www.anthropic.com/news/fable-mythos-access
- Anthropic, Introducing Claude Fable 5 and Claude Mythos 5. https://platform.claude.com/docs/en/about-claude/models/introducing-claude-fable-5-and-claude-mythos-5
- CNBC, Anthropic disables access to Fable 5 and Mythos 5 to comply with government directive. https://www.cnbc.com/2026/06/12/anthropic-disables-access-to-fable-5-and-mythos-5-to-comply-with-government-directive.html
- Tom's Hardware, US export-control order forces Anthropic to disable Claude Fable 5 and Mythos 5 worldwide. https://www.tomshardware.com/tech-industry/artificial-intelligence/us-export-control-order-forces-anthropic-to-disable-claude-fable-5-and-mythos-5-worldwide
- NIST, AI Risk Management Framework (Govern, Map, Measure and Manage functions). https://www.nist.gov/itl/ai-risk-management-framework
- ISO/IEC 42001:2023, Artificial intelligence management system. https://www.iso.org/standard/42001
- Anthropic, Claude Code overview. https://code.claude.com/docs/en/overview
- Anthropic, Claude Code memory. https://code.claude.com/docs/en/memory
- Anthropic, Prompt engineering overview. https://platform.claude.com/docs/en/build-with-claude/prompt-engineering/overview
TheAICommand. Intelligence, At Your Command.


