
You can use AI on regulated data safely by running a five-step privacy assessment before any workflow and choosing an enterprise or tenant-grounded tool, never a consumer chat interface. Regulated work and AI can co-exist. Done badly, they cannot.
Important note for regulated work. This article is general education and not legal, compliance, financial, clinical or professional advice. Your obligations under the Privacy Act 1988, APRA prudential standards, the SRC Act 1988, the relevant state workers compensation legislation, the Australian Privacy Principles, the Anti-Money Laundering and Counter-Terrorism Financing Act, and any sector-specific regulator guidance prevail over anything here. If you are unsure, ask your privacy officer, your compliance team, or counsel before proceeding. The article assumes a reader who has access to those people. Do not rely on it as a substitute for them.
Why this matters
Workers compensation case managers handle some of the most sensitive personal information in any Australian workplace. Governance and compliance officers handle confidential board material, regulator correspondence, and customer data. HR handles complaints, performance, medical certificates and remuneration. Clinical roles handle patient records.
If you sit in any of these roles, the question is not whether you should use AI at work. The question is how to use it without putting confidential information into the wrong system. The wrong system in 2026 is most easily defined as: a consumer chat interface where the data leaves your control, gets retained, and possibly trains a future model.
This article is the practitioner's guide. It is opinionated. It is also the working position taken by privacy offices and regulators across 2026.
What five questions should you answer before using AI on regulated data?
Before any AI workflow that touches data more sensitive than yesterday's coffee order, walk through these five questions. Take five minutes. Write your answers down.
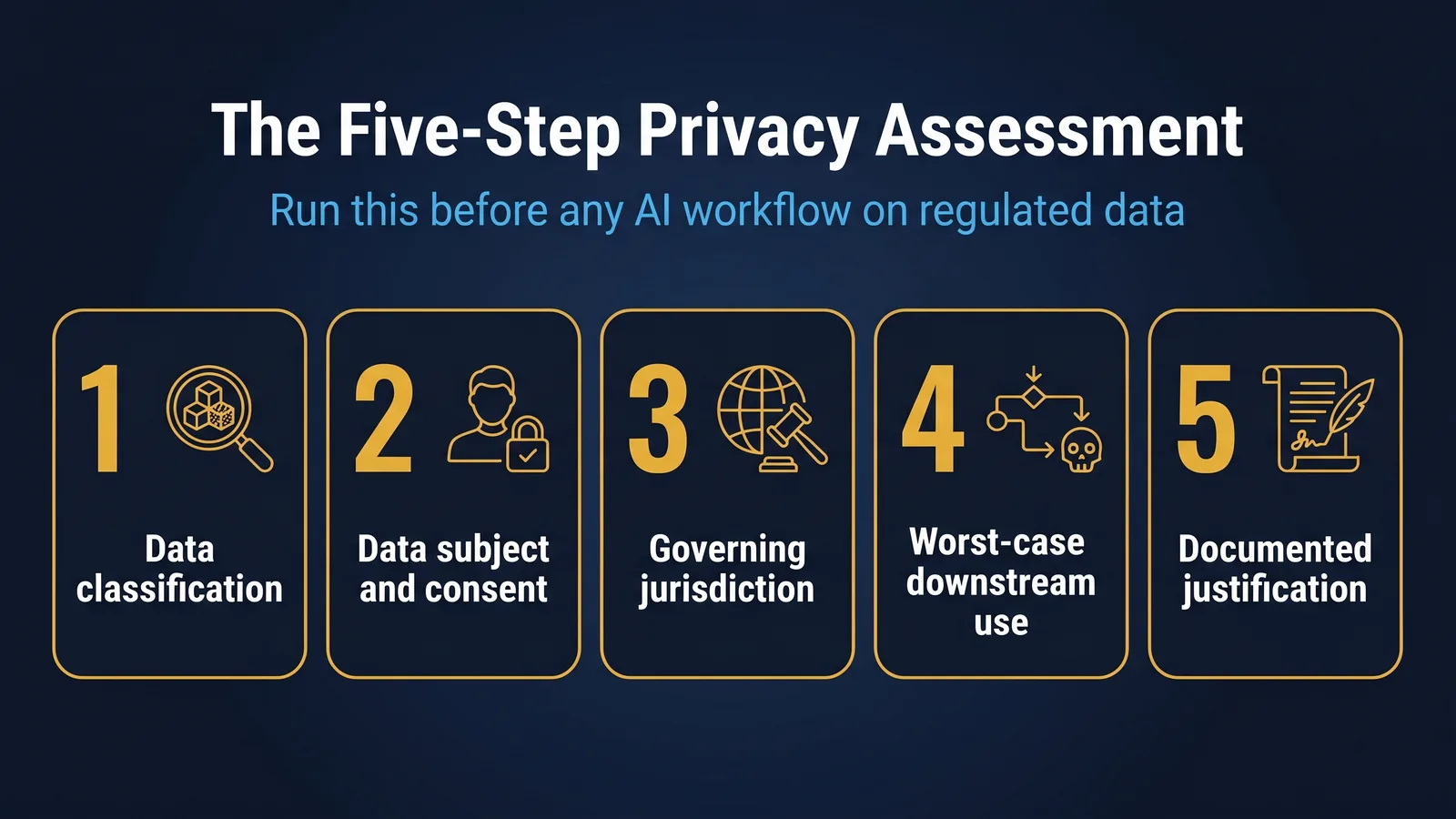
1. What is the data classification
Is this public, internal, confidential, or restricted. Use your organisation's classification framework. If you do not have one, default to "treat anything that names a person, a customer, a claim, a financial position, or an internal process as confidential or higher".
2. Who is the data subject and what consent applies
For workers compensation: the claimant, the employer, the treating practitioner. For HR: the employee. For GRC: the customer, the regulator, the named third party. Each has rights under the Privacy Act and the relevant sectoral regime. Consent for one purpose does not extend to AI processing unless that was contemplated.
3. What jurisdiction governs the data
Australian regulated data has Australian rules. Some sectors require data residency in Australia or in jurisdictions on an approved list. Some prohibit cross-border processing without specific consent or a contractual basis. The tool you pick must respect this.
4. What is the worst-case downstream use
If the prompt and the data leak, what is the worst-case scenario. A claimant's medical history posted on a forum. A customer's identifying details used to train a future model. A regulator's confidential request inadvertently disclosed. The worst-case scenario is the floor for your decision, not the average case.
5. What is the documented justification for using AI on this data
This is the question almost no one writes down. If a regulator or an internal auditor asks why this data went through this tool, what is your documented answer. "It saved time" is not a sufficient answer. "We assessed the privacy posture against APP 11, the tool meets the criteria, and the workflow is documented in our AI register" is.
If you cannot answer all five, do not proceed. The five-step assessment is the gatekeeper, not the prompt.
Which tier of AI tool can you use for regulated data?
Every AI tool you can use at work falls into one of three tiers on data handling. Knowing which tier you are using is the single highest-value privacy decision you make, more so than choosing between Claude, ChatGPT, Gemini or Copilot.
Tier 1: Consumer chat (free or paid personal account)
Examples: a personal Claude account, free ChatGPT, the consumer Gemini app.
Default data handling: prompts may be retained for service improvement and may, in some cases, be used to train future models. Consumer tiers vary. Some allow training opt-out. Some do not. The default cannot be assumed.
Acceptable use for regulated data: never. Do not paste regulated personal information, claim data, customer data, or confidential business material into a consumer tool. Even if you have opted out of training, the prompt has still left your tenant.
Tier 2: Enterprise (paid business or team tier with a contract)
Examples: ChatGPT Enterprise, Claude for Enterprise, Microsoft 365 Copilot under your organisation's tenant, Gemini for Workspace under a Google Workspace agreement.
Default data handling: prompts and outputs are not used to train models. Data is processed in regions specified in the contract. Standard contract terms cover confidentiality and data subject rights. Audit logs are available.
Acceptable use for regulated data: depends on the specific contract, the data classification, and your organisation's privacy assessment. The starting position is "potentially yes, with controls". The work is in the controls.
Tier 3: Tenant-grounded enterprise (Copilot, custom RAG over your own data)
Examples: Microsoft 365 Copilot grounded in your tenant, Claude or ChatGPT integrated via API into your own private RAG system, Glean and similar enterprise search assistants.
Default data handling: data never leaves your tenant. The model is given the question and a controlled retrieval, the pattern RAG explained for non-engineers walks through. Outputs reference your own documents. Training opt-out is the default. Data residency follows your tenant's contracted region.
Acceptable use for regulated data: highest fit. Still requires the five-step assessment, but the architecture itself does most of the privacy heavy lifting.
The practical implication: if you are doing regulated work and your organisation has not yet provided you with a Tier 2 or Tier 3 tool, your AI use at work should be limited to non-confidential tasks until they do.
De-identification is necessary, not sufficient
The most common workaround for regulated work is de-identification. Strip the names. Strip the dates. Strip the claim numbers. Then paste the de-identified text into the consumer tool.
This is better than not de-identifying. It is not a complete answer, for three reasons.
Re-identification risk. A claimant in a small region with a rare condition can sometimes be identified from supposedly de-identified data. The smaller the population and the rarer the attributes, the higher the risk.
Residual confidentiality. Even if the personal information is removed, the document may still contain confidential business information, internal procedures, or regulator correspondence.
Volume and pattern. A de-identified single case may be safe. A de-identified hundred cases pasted in over a year creates patterns that, in aggregate, may not be safe.
De-identification is a tool. It is not the whole toolkit. Tier 2 or Tier 3 deployment, plus de-identification where appropriate, is the working position for serious regulated work.
What do Australian regulators expect for AI use?
Three Australian regulators have published or signalled positions on AI use in 2025 and 2026 that this article assumes.
The Office of the Australian Information Commissioner (OAIC) has been clear that the Privacy Act 1988 applies to AI processing of personal information. Existing obligations under the Australian Privacy Principles continue to apply, and a privacy impact assessment is the expected first step before any regulated AI use.
APRA has signalled, through CPS 230 (operational risk management) and through its 2026 thematic review on model risk, that AI tools used in APRA-regulated entities are within the scope of operational risk and model risk frameworks. Boards are expected to understand the controls.
Comcare, for SRC Act schemes, has issued guidance on AI use in claims handling that emphasises de-identification, documented decision-making, and the non-delegability of statutory determinations. The model assists. The decision belongs to the delegate.
These are not the only regulators that matter, and the positions evolve. The pattern, though, is consistent. Existing law applies. The novelty is in the application, not in the obligations.
A documented workflow template
For any AI workflow that touches regulated data, document the following.
- The purpose, named and bounded
- The data classification and the data subjects affected
- The tool, the tier, and the contractual basis (or "no contract, consumer tier, only non-regulated data permitted")
- The de-identification step, if any
- The retention and deletion expectation
- The human review step (named role, named action)
- The escalation path if the tool produces an output that should not be relied on
- The owner, the reviewer, and the review cadence
This becomes part of your AI register. It is the document you hand to a regulator, an internal auditor, or your replacement when you leave the role. Workflows without this documentation are not workflows. They are habits, and habits are not defensible.
Common mistakes
Trusting the consumer tier with regulated data because the company name is famous. OpenAI, Anthropic and Google all run consumer tiers and enterprise tiers separately. Famous brand does not equal enterprise contract. The contract is what you rely on.
Assuming "I have a paid account" means enterprise. A personal paid account is still consumer tier. Enterprise tier is contracted at the organisation level.
Paste-now, document-later. Documentation that does not exist before the work happens is documentation that will not exist after. Build it into the workflow design.
Treating the AI as the decision-maker. Regulated work decisions belong to a human, named in your file, with the authority to make that decision. The AI assists. The AI does not decide.
Assuming de-identification scales. It works case by case. It does not necessarily work at the volume and pattern level.
A worked example
A workers compensation case manager is preparing a section 14 determination on a complex claim. The file note runs to 30 pages. She wants to use Claude to draft a structured summary of the evidence.
Wrong approach: paste the file note, with the claimant's name, address, claim number and treating practitioner names, into her personal Claude account. This is a privacy breach.
Acceptable interim approach: de-identify the file note (remove names, replace claim number with a placeholder, generalise dates). Paste the de-identified text into her personal Claude account, knowing it is consumer tier. Use the output as a structural prompt only, then write the actual determination herself using the original file. Document the workflow in her team's register.
Best practice: her organisation provides her with a Tier 2 or Tier 3 enterprise tool. She uses that, with the file note unchanged. Output is grounded in her tenant. Audit log captures the interaction. The five-step assessment lives in the AI register.
The interim approach is acceptable in 2026 because the tool ecosystem is still maturing. The best practice approach is what every regulated organisation should be working towards by 2027.
What "good" looks like in 2026
Three markers, taken together, distinguish a regulated team using AI well from one using AI carelessly.
Tier 2 or Tier 3 deployment as the default. Staff have access to an enterprise tier or a tenant-grounded tool, and that is the tool they reach for first. Consumer tier use is reserved for non-confidential work and is documented as such.
An AI register that is current. Each material AI workflow has an entry. The entries name the purpose, the tool, the data classification, the human reviewer, and the review cadence. New workflows are added before they go into production, not after.
A regular conversation between practitioners and the privacy office. The privacy officer does not first hear about a new AI workflow when something has gone wrong. Practitioners bring proposals before they build them. The privacy office gives risk-graded advice rather than blanket prohibitions. Both groups treat the other as colleagues, not as obstacles.
The third marker is the most predictive of the three. Teams whose privacy office and operational staff are talking regularly tend to land the first two markers in time. Teams where the two groups only meet during incidents do not.
Try this
Pick a real document you worked with this week. Walk it through the five-step privacy assessment in this article. Identify which tier of tool would be appropriate for that document, and which would not. If your organisation has not deployed a Tier 2 or Tier 3 tool yet, this is the conversation to take to your privacy officer or your manager.
Glossary
De-identification. Removing or replacing information that can identify an individual.
Re-identification risk. The risk that data described as de-identified can be linked back to a person.
Tenant. Your organisation's instance of a cloud service.
Data residency. The country where data is processed and stored.
Training opt-out. A vendor setting that prevents your prompts and outputs from being used to train future models.
Where to go next
- Reading an AI Tool Safety Card
- RAG Explained for Non-Engineers
- Choosing Claude, ChatGPT, Gemini or Copilot for Your Job
Bottom line
AI and regulated work can co-exist, but only when a five-step privacy assessment gates every workflow and the tool sits in Tier 2 (enterprise) or Tier 3 (tenant-grounded), never a consumer chat interface. De-identification helps but is not a complete answer. The decision stays with the named human, and the workflow lives in your AI register.
Do this Monday:
- Run the five-step privacy assessment on one real document you handled this week.
- Confirm which tier your current AI tool sits in, and if it is consumer, restrict it to non-confidential work.
- Check whether your organisation has deployed a Tier 2 or Tier 3 tool, and raise it with your manager if not.
- Write one AI workflow into your AI register with a named human reviewer and a review cadence.
- Book a standing conversation between your team and the privacy office before an incident forces one.
TheAICommand. Intelligence, At Your Command.


