
ChatGPT just got materially better at answering health questions.
On 18 June, OpenAI announced a substantial step forward in ChatGPT's health intelligence, driven by its GPT-5.5 Instant model. On its hardest health evaluations, OpenAI says GPT-5.5 Instant now performs at a level comparable to its frontier Thinking models. Because that model is free for everyone in ChatGPT, the improvement reaches the broadest possible audience. The development on its own is one capability update. What it changes for anyone who works near health, privacy or claims is the part worth your attention.
What actually happened
More than 230 million people already turn to ChatGPT every week for health and wellness questions: making sense of symptoms, reading lab results, preparing for appointments, navigating insurance. OpenAI reports that across billions of health messages a week, the rate of responses with at least one flagged factuality issue has fallen 71 per cent over the past two months. The model is now better at recognising when urgent care may be needed, asking for relevant context, explaining uncertainty, and putting complex information into plainer language.
The work sits on a physician-led evaluation programme. OpenAI says it works with a global network of more than 260 physicians across 60 countries and 26 medical specialties, who have reviewed more than 700,000 example responses. In one comparison, a separate panel of doctors rated GPT-5.5 Instant's written answers higher than answers physicians had written themselves with unlimited time and internet access. Hold that result lightly. We will come back to it.
What it actually means
The headline is not a new model. GPT-5.5 Instant shipped in May. The shift is that competent health information is now default infrastructure: free, in everyone's pocket, and good enough that people will act on it. For two years, AI health answers came with a heavy "do not rely on this" asterisk. That asterisk is shrinking, and OpenAI is putting the result in front of 230 million weekly users with no paywall.
For Australian professionals, this is a duty-of-care and governance question before it is a productivity one. Your staff, your clients, and in regulated work your claimants are already using this. It is going to be more confident, more often right, and harder to wave away. The question is no longer whether people use AI for health. It is what your organisation does about the gap between a good answer and a clinical decision.

Who should care, and why
Privacy first. Under the Privacy Act 1988, health information is sensitive information, and the OAIC is explicit that sensitive information is "generally afforded a higher level of privacy protection under the APPs than other personal information". An entity should "generally seek express consent" before handling it. A consumer chatbot is not the place for an employee's diagnosis or a claimant's medical history. The moment health or claims detail goes into a general-purpose tool, you have a collection-and-disclosure question your privacy framework has to answer for, and a higher consent bar than ordinary personal information.
For workers compensation, the line is sharper still. Liability and medical questions are decided on medical evidence from qualified practitioners, not on a chatbot's summary. A claimant who arrives having asked ChatGPT what their MRI report means is better informed, and that is fine. A case manager who lets an AI summary stand in for an independent medical opinion has a problem. AI can help a claimant prepare for an appointment. It cannot be the appointment, and it is not evidence.
For registered health practitioners, the responsibility for any decision stays with the person, not the tool. ChatGPT is a general-purpose assistant, not a registered clinical system, and OpenAI positions it as informational. Better information is genuinely useful at the edges: for working out what to ask, for a plain-language explanation of a term. It does not move where the accountability sits.
The hype check
Two cautions are worth naming. First, that "rated higher than physicians" result is a written-response evaluation, not a clinical trial. Doctors wrote answers, and a panel scored both the human and the model answers against rubrics. Scoring well on written health questions is not the same as assessing a patient in front of you, with examination, history and consequences. It is a real and impressive evaluation result. It is not "AI is better than your doctor", and OpenAI does not claim that.
Second, 71 per cent fewer flagged factuality issues is a large improvement and still not zero. On billions of messages, a smaller share of a much larger number is still a lot of confident, wrong health answers reaching people who cannot tell. "Comparable to a frontier model on the hardest evals" means very good. It does not mean safe to act on without judgement, and the people most likely to over-trust a polished answer are often the ones least able to check it.
Putting the boundary to work: a plain-English summary with a review gate
Here is where the theory becomes a workflow. Regulated professionals in insurance, superannuation and banking constantly receive dense clinical or medical-legal material: an independent medical examiner's report, a treating specialist's letter, a functional capacity evaluation, an income protection medical assessment. Reading it is slow, and the jargon is a barrier for the claimant or member who has to act on it. This is exactly the kind of task AI is good at, and exactly the kind of task that needs a hard human gate.
The pattern is simple and safe when you hold two rules. First, the AI produces a plain-English summary to aid understanding, never a clinical opinion, a liability view, or a recommendation. Second, a qualified person, the treating practitioner, an independent medical examiner, or the appropriately delegated decision maker, reviews and owns the outcome. AI informs. A person decides.
A standing data rule before you run anything below. Never paste real personal, claim, health or incident data into a model that is not an approved enterprise instance. Health information is sensitive information under the Privacy Act 1988, and the OAIC sets a higher consent bar for it. The prompts below use placeholder tokens like [CLAIMANTNAME], [CLAIMNUMBER] and [DATE] on purpose. De-identify first, then run.
This prompt takes a de-identified clinical document and produces a plain-English summary with the review gate built into the output itself, so the boundary travels with the work.
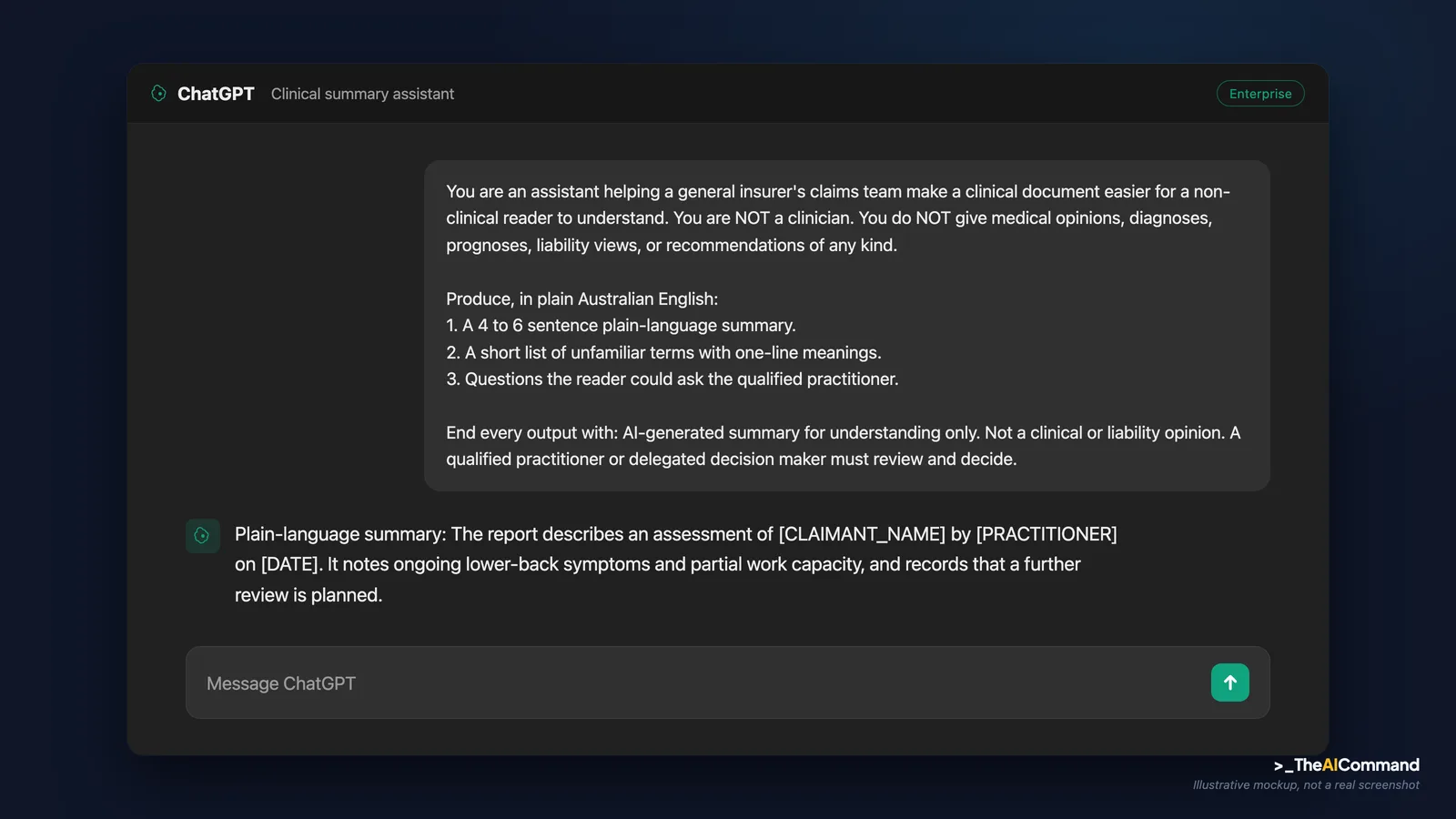
If you want the boundary enforced every time rather than relying on one prompt, set it once in a project space. In ChatGPT Projects (or Claude Projects), create a dedicated project, paste the block below into the custom instructions, and the rules apply to every chat inside that project.
Files to upload to the project space (de-identified only): your organisation's AI acceptable-use policy, your de-identification standard or checklist, a one-page glossary of common medical-legal terms your team meets, and a blank claimant-facing summary template if you have one. Do not upload real claim files, medical reports with identifiers, or anything you would not put in an email to an external party.
One worked walkthrough, de-identified
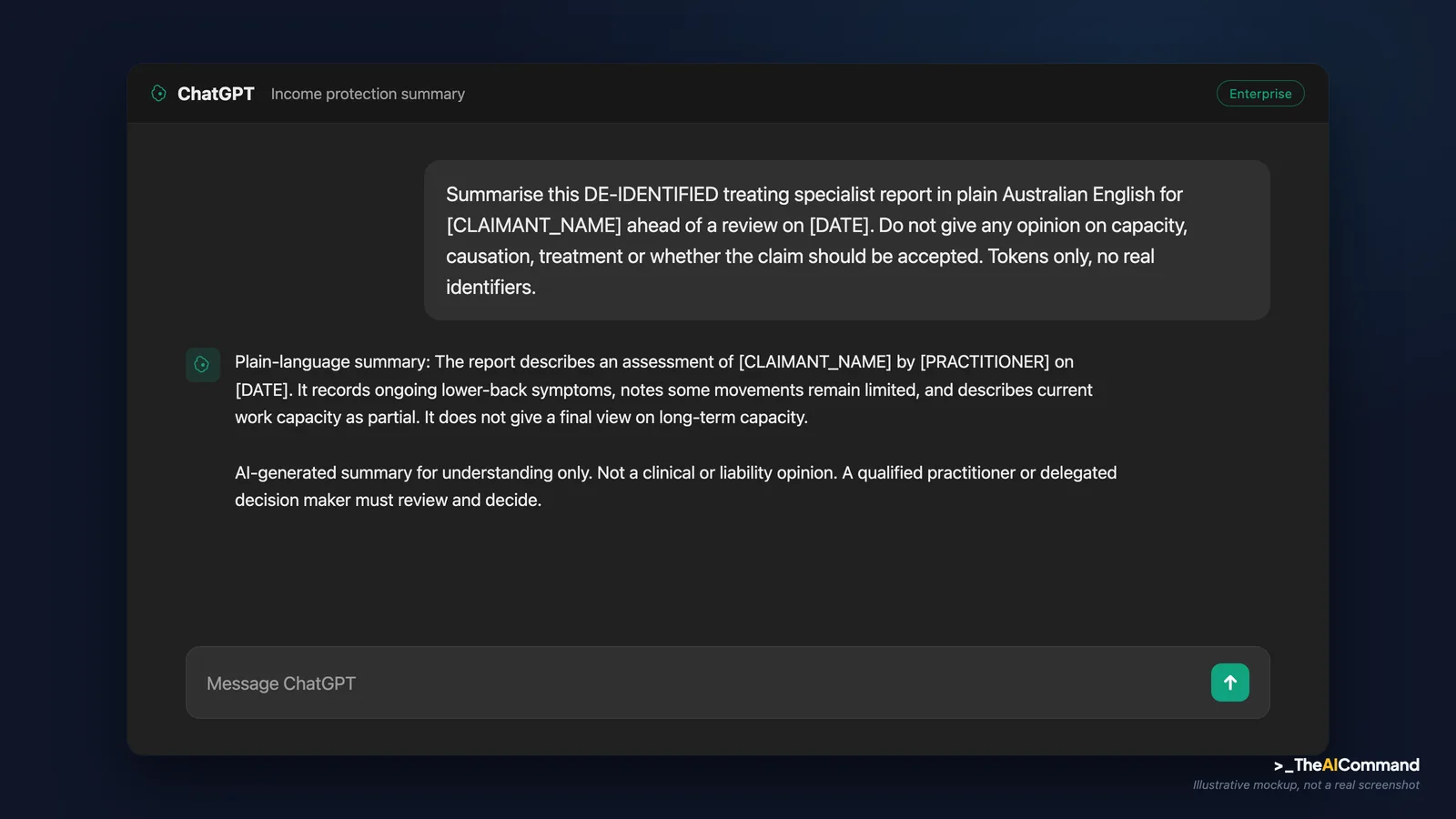
A general insurer's income protection team receives a treating specialist's report on a claim. The claims officer, [ROLE], needs to brief the claimant, [CLAIMANTNAME], on what the report says in language the claimant can follow, ahead of a review on [DATE]. The report is dense.
Step one, de-identify. The officer replaces every identifier in the document with tokens: name to [CLAIMANTNAME], the claim reference to [CLAIMNUMBER], the specialist to [PRACTITIONER], dates to [DATE]. The de-identified text goes into the approved enterprise instance, inside the project space set up above. No identifiers leave the approved environment.
Step two, run the summary prompt. An illustrative output:
Step three, the human decision gate. This is the step that cannot be skipped. The summary is a comprehension aid, not evidence and not a decision. The claims officer does not act on the summary. The delegated decision maker reviews the underlying report against the medical evidence and the relevant scheme rules, and any clinical question goes back to the qualified practitioner. The claimant gets a plainer explanation of the report; the determination still rests entirely on the practitioner's evidence and the delegate's judgement. AI made the document readable. It did not make the decision, and the disclaimer line travelling with the output keeps that boundary visible to everyone who touches the file.
What to do this week
You do not need to ban anything. You need to set the data line and name the boundary before someone crosses it for you.
- Set the data line. Tell your team plainly: no employee health information, no claimant medical detail, no identifiable clinical data goes into a consumer AI tool. Health information is sensitive information, and the consent bar is higher.
- Name the boundary out loud. Decide where AI health information is welcome, such as preparing questions, explaining a term, or general wellbeing, and where it is not, such as a diagnosis, a clinical decision, or medical evidence in a claim. Write it down once.
- Brief the front line. Case managers, HR and people leaders will meet clients and staff who arrived with an AI health answer. The move is to acknowledge it, then route the decision to the qualified person. AI assists. A clinician or a delegate decides and signs.
- Revisit your own guardrails. If your organisation already uses AI for any health-adjacent work, treat this jump as a reason to check your controls, not relax them. Better output raises the temptation to skip the human check, which is exactly when you should not.
The story vendors will tell is that AI health advice has arrived. The truer story is that good health information is now free and everywhere, and the value of a qualified human judgement just went up, not down. The organisations that handle this well will be the ones that drew the line early, between information anyone can get and a decision someone has to own. Not the ones who find the line during a complaint.
References
- OpenAI, Improving health intelligence in ChatGPT, 18 June 2026. https://openai.com/index/improving-health-intelligence-in-chatgpt/
- OpenAI, HealthBench (health evaluation referenced in the announcement). https://openai.com/index/healthbench/
- OAIC, APP Guidelines, Chapter B: Key concepts (sensitive information includes health information; higher protection; express consent). https://www.oaic.gov.au/privacy/australian-privacy-principles/australian-privacy-principles-guidelines/chapter-b-key-concepts
General information and education only. Not medical, legal, compliance or professional advice. AI health output is not a substitute for a qualified clinician, and is not medical evidence. Verify anything that matters against the primary sources and the right professional before acting.*
TheAICommand. Intelligence, At Your Command.


