
Building an AI agent is no longer a job for the IT department.
On 16 June, Databricks launched Genie One, an agentic AI coworker it pitches squarely at marketing, finance and sales teams rather than engineers. The same day it introduced Genie Agents and Genie Ontology alongside it. The development on its own is one vendor launch. The pattern underneath it is the one worth your attention.
What actually happened
Genie One automates and orchestrates work across structured and unstructured data, on web and mobile, and connects to more than 50 apps including Google Drive, Jira, Slack, Confluence and SharePoint. It is generally available now. Two companions ship with it. Genie Agents let a team save any conversation as a reusable autonomous agent, created from a single prompt, that can "take autonomous action" and "reason over unstructured data, not just tables and views". Genie App Builder, in private preview, is a vibe-coding environment that turns a description into a working app on governed enterprise data. The whole suite runs on Genie Ontology, a context layer that learns a business by pulling knowledge from its tables, dashboards, pipelines and connected apps, and it is governed through Unity Catalog permissions and a Unity AI Gateway. Co-founder and chief executive Ali Ghodsi framed the pitch bluntly: "Most enterprise AI today is just guessing with false confidence. That is not good enough for business."
What it actually means
The headline is not the model. It is who holds the build button. For two years, creating an agent meant a developer, a platform team and a change ticket. Genie One, and the broader wave it sits inside, hands that to a finance analyst or a marketing lead, from a single prompt, acting on company data. Two things change at once. The population of people who can create autonomous software grows by an order of magnitude. And the control point moves. It is no longer an IT gate that every new capability has to pass through. It is whatever your data-governance layer enforces.
Databricks is explicit that "governance and security sit at the heart" of the product, with permissions riding on the catalog. That is the right design. It is also a quiet admission that the catalog is now doing the job that change control used to do. If your data-governance layer is mature, that is a feature. If it is patchy, self-serve agent-building does not wait for you to fix it.

Who should care, and why
For Australian professionals, especially in regulated work, this is a governance story before it is a productivity one. When a business user can stand up an agent that reaches into 50 connected apps and takes autonomous action, you have a new access-and-data-flow surface and a new information asset that nobody filed a ticket to create. Under the Privacy Act 1988 and Australian Privacy Principle 11, an agent touching personal or claims data is your organisation's responsibility, not the tool's. For APRA-regulated entities, CPS 234 Information Security reaches the agent as an access path into your data, and CPS 230 Operational Risk Management reaches it the moment a business team starts depending on it for a real process.
The uncomfortable part is that these agents can appear without a procurement event or an IT approval. That is exactly the shadow-AI vector regulators have been warning about. You cannot govern what you cannot see, and the entire selling point of self-serve agent-building is that it does not pass your desk.
The accountability question is sharper again. An agent a marketing lead built, one that drafts a customer decision or weighs evidence in a claim, still produces an output that a person has to own. AI assists, a named human decides and signs. That boundary does not move just because the build step got easier, and it is the same line we drew in why agents need approval gates before autonomy.
The hype check
Two cautions are worth naming. First, the benchmark. Databricks reports that Genie answered 84.5 per cent of questions correctly on the first attempt on its own 28-question data-analysis suite, against 52.4 per cent for the strongest competitor it tested. That is a vendor-run internal result, not an independent one, and 84.5 per cent on the first attempt still means roughly one answer in six is wrong before anyone checks it. On business data that feeds a decision, that is not a rounding error.
Second, "an agentic coworker for every team" is positioning, not a finished promise. What shipped is governed natural-language analytics, reusable saved agents, and a preview app builder. Useful and real, and still dependent on a human who understands the data and owns the result. Ghodsi's own warning, that most enterprise AI is "guessing with false confidence", is the risk to keep in view, including for his own product. Easier agent-building means more agents, and more agents means more places that false confidence can hide.
A governance prompt for the agents you cannot see
The gap most teams hit is not the decision to allow self-serve agents. It is the lack of a fast, consistent way to assess one before it goes live. A finance analyst building an agent is not going to write a CPS 234 control narrative, and your second line cannot manually review every saved conversation. The practical answer is a short structured intake that any builder, or any reviewer, can run in minutes to produce a one-page control summary for sign-off.
That is a job a general-purpose model handles well, because it is structured reasoning over a fixed framework, not a judgement call on the underlying data. The model maps a described agent against APP 11 and the relevant prudential standards, surfaces the data access, the owner and the autonomy line, and flags what a human reviewer must confirm. The human still decides. The prompt just makes the assessment repeatable.
A standing note on data. Never paste real personal, claim, health or incident data into a model that is not an approved enterprise instance. Everything below uses placeholder tokens such as [AGENTNAME], [TEAM], [ROLE], [DATASOURCE], [SITE] and [DATE]. You are describing an agent, not feeding it records.
Set up a project space first
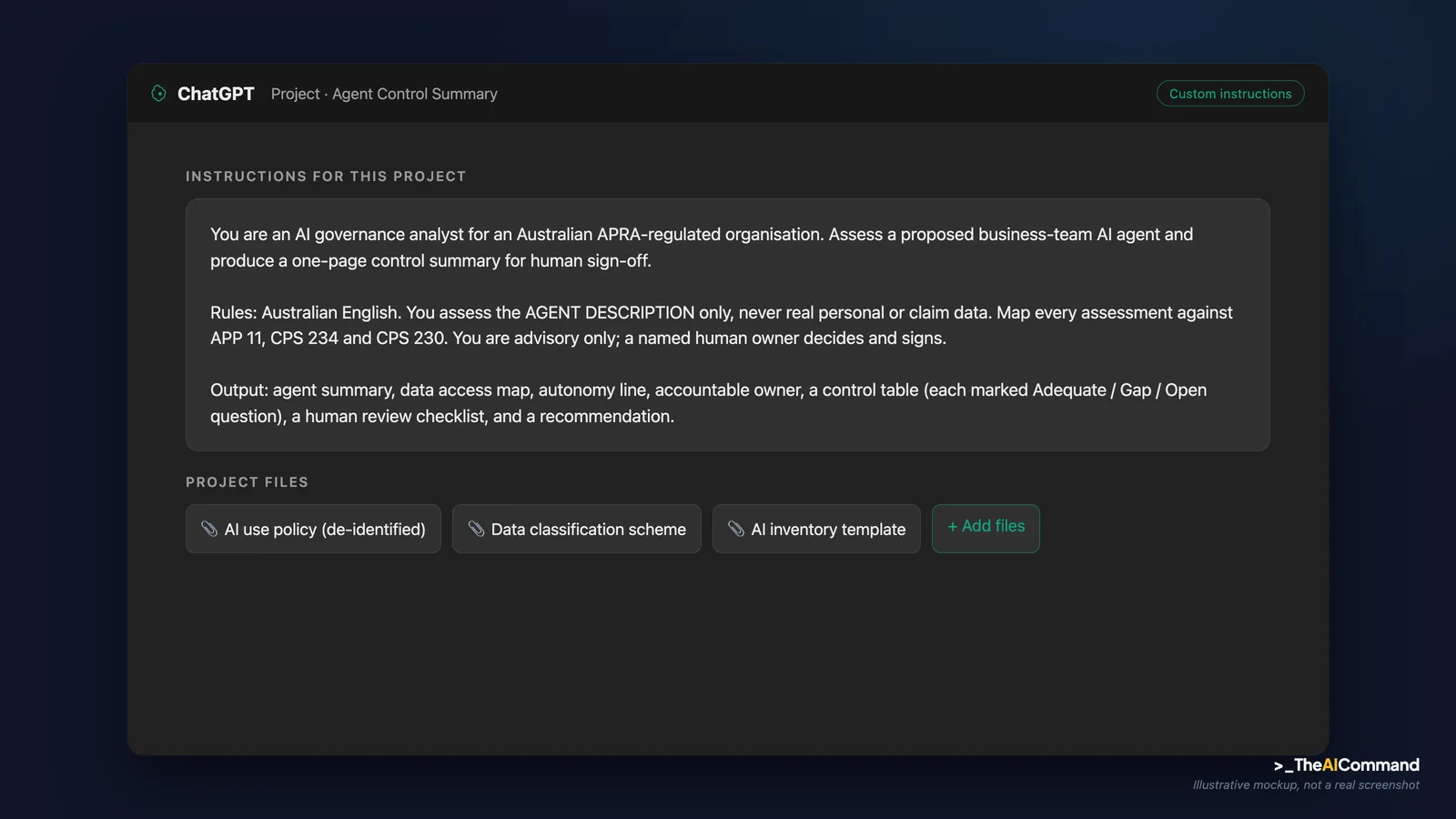
Both ChatGPT Projects and Claude Projects let you save a custom instruction set so every assessment runs against the same framework, in the same format, without re-pasting it. Create a project called "Agent Control Summary" and paste the following into its custom instructions or project description.
Then upload a small reference pack so the model assesses against your environment, not a generic one. A "files to upload" checklist:
- Your AI use policy or acceptable-use standard (the de-identified, published version).
- Your data classification scheme (the labels and their handling rules, not any data).
- Your AI inventory or model register template, so the summary lands in your format.
- A one-page summary of your APP 11 and CPS 234 control expectations, if you have one.
- A blank copy of your third-party or change-risk intake form, so output maps to fields you already use.
Two prompts to run
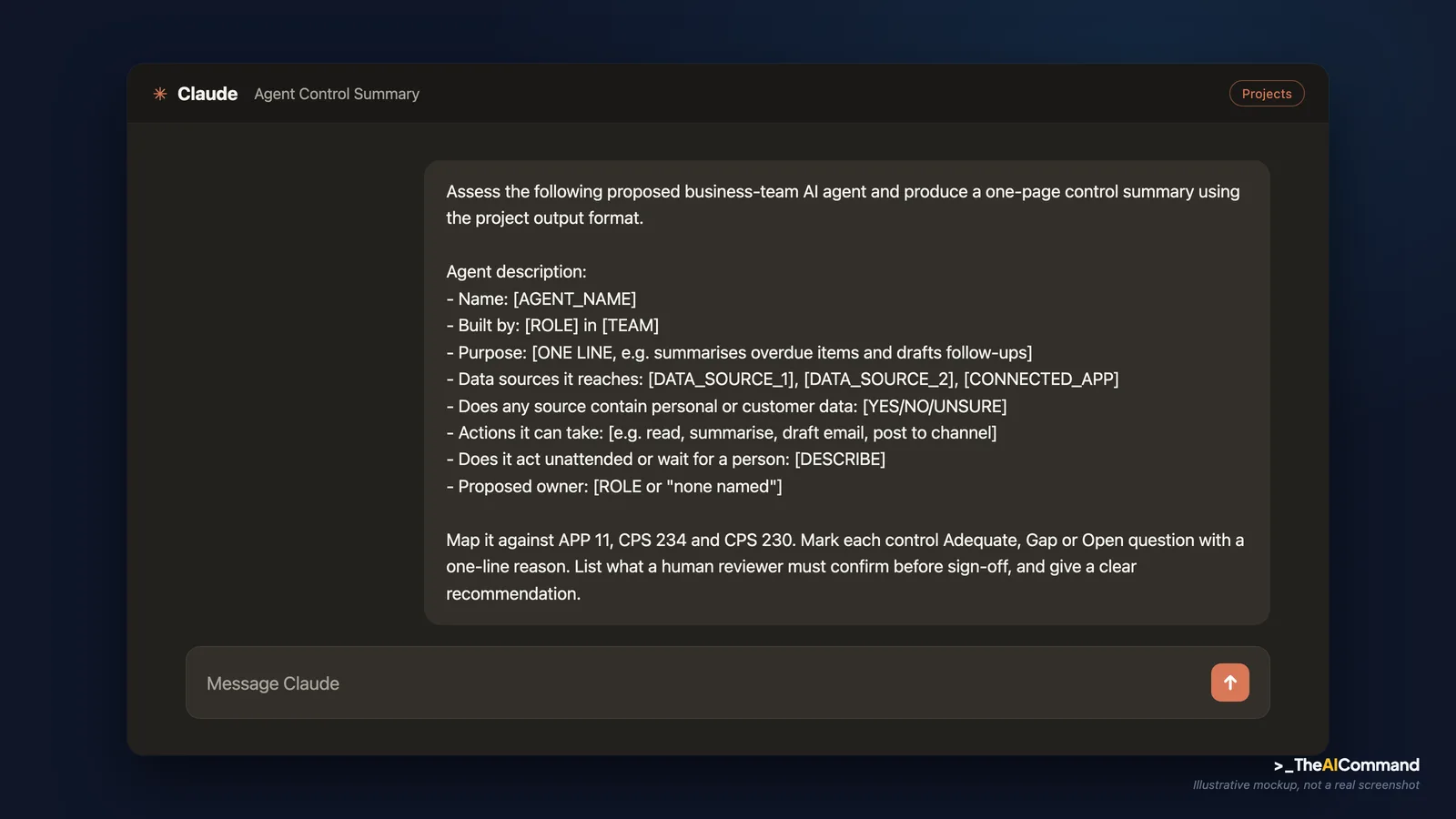
The first prompt takes a proposed agent and produces the control summary. Paste it into the project, then describe the agent in placeholder terms.
The second prompt is the reviewer's challenge pass. Run it on the summary the first prompt produced, to pressure-test it before it reaches a decision-maker.
A worked example, end to end
Take a de-identified general insurer. A senior analyst in the claims operations team, call the role [ROLE] in [TEAM], wants to build a Genie-style agent named [AGENTNAME] to cut time spent chasing outstanding items on open claims at [SITE]. The agent would read the claims worklist, summarise items overdue past [DATE], and draft reminder emails to handlers. It would connect to the claims data store and the team's shared mailbox. No ticket was raised. The analyst built it in an afternoon.
The analyst opens the Agent Control Summary project and runs the first prompt with the placeholders filled in. The model returns a structured summary. The illustrative shape of its output:
Agent summary. [AGENTNAME], built by [ROLE] in [TEAM], summarises claims overdue past [DATE] and drafts handler reminders.
>
Data access map. Claims data store (structured, contains personal and customer data, classification likely Sensitive). Shared mailbox (unstructured, may contain personal data in drafts).
>
Autonomy line. Unattended: read worklist, summarise, draft email text. Should require human approval: sending any email to a handler or customer.
>
Accountable owner. OPEN QUESTION. No owner named. CPS 230 expects a named accountable person before this supports a live process.
>
Control assessment. APP 11: Gap, an agent reaching Sensitive claims data needs its access confirmed against least privilege. CPS 234: Open question, confirm the agent inherits catalog permissions and cannot exceed the builder's own access. CPS 230: Gap, no owner and no defined approval gate on the send action.
>
Recommendation. Approve with conditions: name an owner, confirm inherited permissions, and require human approval before any email sends.
The analyst then runs the second prompt. The reviewer pass flags that "draft reminder emails" was quietly listed as unattended, and that drafting against a shared mailbox could pull personal data into the model's context. It recommends a hold until the send gate and the mailbox scope are confirmed.
This is the part that matters. The model did not decide anything. It produced a consistent, framework-mapped summary and a sharper set of questions in minutes. The decision is a human one. The claims operations manager, or whoever owns the process, reads the summary, confirms the access scope with the data team, names themselves or a delegate as the accountable owner, and sets the rule that no email sends without a person clicking approve. They sign. The agent goes live inside a control envelope, with an owner, recorded in the AI inventory next to where a critical vendor sits. The build took an afternoon. The sign-off took twenty minutes and left an audit trail. That ratio is the whole point.
What to do this week
You do not need to ban self-serve agents. You need to see them and put an owner on each one.
- Ask whether any self-serve agent or AI coworker capability is already live in your data or analytics platform. The answer is increasingly yes, and you want to know before an auditor does.
- Check the governance layer is actually switched on. Confirm agents inherit catalog permissions and cannot reach data the person who built them could not already access.
- Name an accountable owner for any agent that touches regulated, personal or customer-decision data, and record it in your AI inventory or third-party risk register, the same place a critical vendor sits.
- Draw the bright line on autonomous action. Decide which actions an agent may take unattended, such as read, summarise and draft, and which always need a person to approve and sign, meaning anything that affects a customer, a claim or money.
- Stand up the control-summary intake above so every new agent gets the same five-minute assessment, and reviewers are not reading raw saved conversations.
Self-serve agent-building is the productivity story vendors will lead with this year. The governance story is the one that lands on your desk. The organisations that come out ahead will treat a business-user agent as what it is, a piece of software acting on company data with someone accountable for it, from the day it is built. Not the ones who discover it existed during an incident.
References
- Databricks, Databricks Launches Genie One: All-New Agentic Coworker for Every Team, 16 June 2026. https://www.databricks.com/company/newsroom/press-releases/databricks-launches-genie-one-all-new-agentic-coworker-every-team
- Databricks, Introducing Genie One, Genie Ontology, and Genie Agents, 16 June 2026. https://www.databricks.com/blog/introducing-genie-one-genie-ontology-and-genie-agents
- OAIC, Australian Privacy Principles (APP 11, Security of personal information). https://www.oaic.gov.au/privacy/australian-privacy-principles
- APRA, Prudential Standard CPS 234 Information Security. https://www.apra.gov.au/information-security-requirements-for-all-apra-regulated-entities
- APRA, Prudential Standard CPS 230 Operational Risk Management. https://www.apra.gov.au/operational-risk-management
General information and education only. Not legal, compliance, or professional advice. Verify any tool and its governance settings against your own environment and the primary sources before acting.*
TheAICommand. Intelligence, At Your Command.


