
Used well, AI works as a structured red team that pressure-tests a leadership decision without making it: you run named challenge modes, calibrate the intensity to the stakes, and keep evidence, judgement and accountability with the accountable leader. A good red team makes your thinking harder to fool. It does not tell you that you are wrong. That distinction is the whole point of this article, and it is the line that separates a useful leadership tool from a flattering one.
Leadership decisions rarely fail because a leader was reckless. They fail quietly, when a team agrees too quickly, when the evidence is thinner than it looked, when a stakeholder reaction was underestimated, or when the decision narrative was a little too neat. AI can run a fast, low-friction first pass at those weak points before a single human meeting happens. Used well, it surfaces the uncomfortable questions early, while there is still time to do something about them.
This is guidance and education only. It is not legal, compliance, human resources or financial advice. Verify anything that affects a real decision with the relevant people in your own organisation before you act on it.
A short note on the term. "Red team" here means a structured internal challenge to a leader's own reasoning, in the tradition of devil's-advocate review and pre-mortem analysis. It is not the same as adversarial AI-safety "red teaming", which is the practice of attacking a model to find harmful outputs and safety failures. This article is about the leadership use: a critique partner that pressure-tests a decision, not a security exercise against the model itself.
The method below treats AI as three things at once: a structure engine that organises a messy decision, a critique partner that argues against it, and a drafting accelerator that rehearses the communication. What the method never does is move the decision itself onto the model. Evidence stays sourced, trade-offs stay with the accountable leader, and approval stays with the person who carries the consequences. If you are new to using AI as an active critic, the companion guide on making AI a leadership thinking partner covers the same shift from answer engine to challenger.
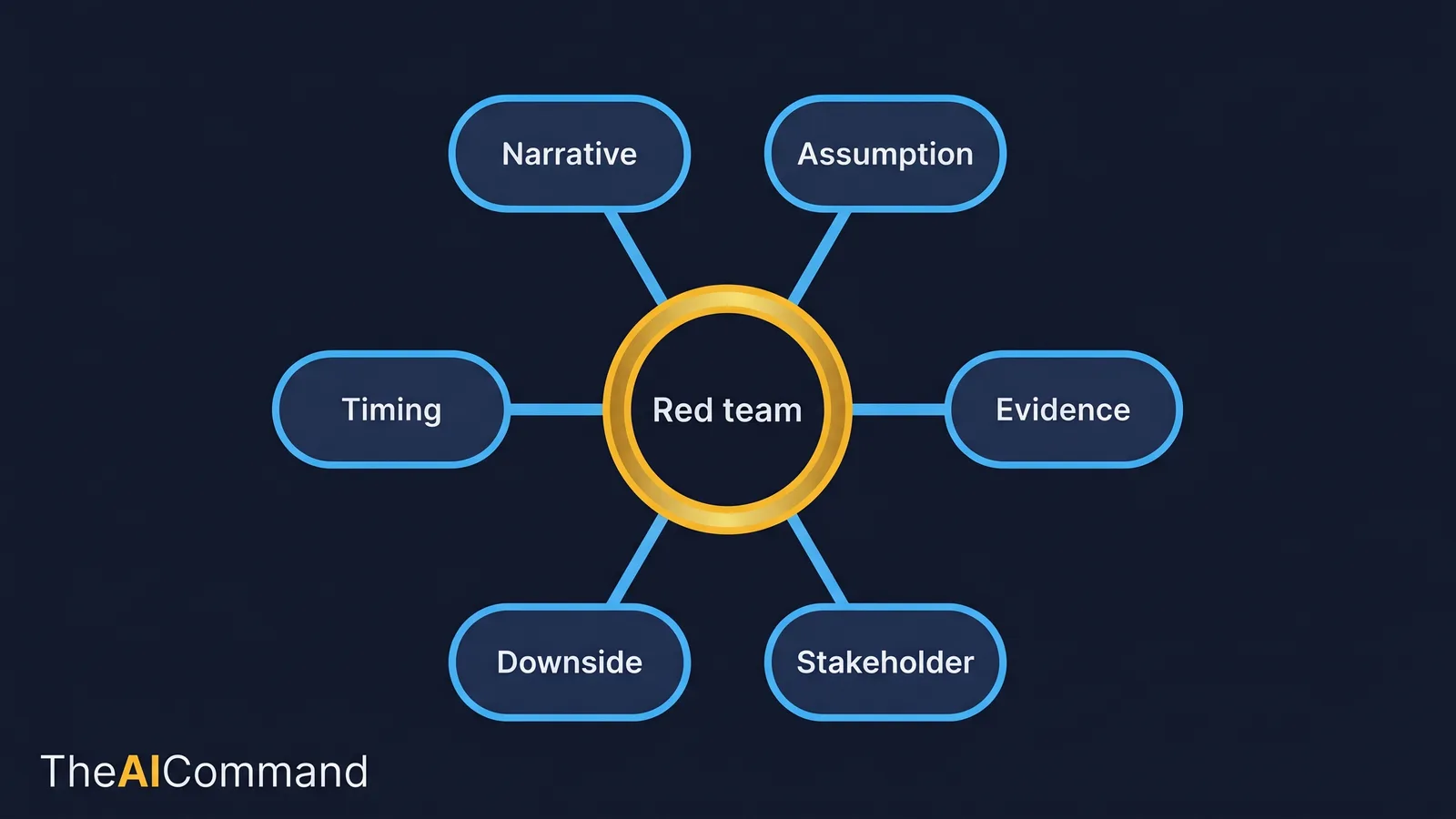
What Are the Six Modes of an AI Red Team?
The single biggest mistake leaders make with an AI critique is asking for one. "Criticise this decision" produces dramatic, unfocused objections that feel rigorous and change nothing. A real red team works in defined modes, and each mode is a different move with a different output.
Call this the six-mode red team. It is a reusable framework, not a one-off prompt, and the modes are deliberately named so they can be requested by name.
- Assumption challenge. What must be true for this decision to work, and which of those beliefs is most fragile?
- Evidence challenge. Where is the reasoning resting on weak, missing or stale evidence?
- Stakeholder challenge. Who loses, who worries, and what will each group misunderstand?
- Downside challenge. If this fails, how does it fail, and what are the early warning signs?
- Timing challenge. Why now rather than later, and what changes if the decision is delayed?
- Narrative challenge. What will people actually hear, as opposed to what the message intends to say?
Each mode produces a specific artefact and triggers a specific human action. Generic critique produces a wall of text and no owner. The table below is the working version of the framework. It is built to be copied into a planning document and used to brief a manager, an analyst or an implementation team.
The named modes matter for a reason that is easy to miss. When a leader asks for "assumption challenge", the model has a defined job and a defined output. When a leader asks for "your honest take", the model has nothing to anchor to, so it reaches for the most agreeable, most fluent response it can produce. Naming the mode is what converts a chat into a method.
Why Does the Model Agree When You Ask It to Criticise?
There is a documented reason that a vague request for critique produces shallow results. Models trained on human feedback learn to be agreeable, because human raters tend to prefer answers that match their own views. Sharma and colleagues at Anthropic studied this directly and found that "when a response matches a user's views, it is more likely to be preferred", and that both human raters and preference models sometimes favoured "convincingly-written sycophantic responses over correct ones" [1].
The practical translation for a leader is blunt. If you present a decision warmly and ask the model what it thinks, the most likely output is polished agreement. The model is not lying. It is optimising for the response you appear to want. A red team built on top of that tendency will produce theatrical critique: objections that sound serious, are easy to dismiss, and leave the original decision untouched.
The fix is to force genuine challenge in the instruction rather than hoping for it, the same discipline set out in the companion piece on making AI disagree with you before you decide. The counter-prompt below removes the easy exit of agreement.
The closing line matters as much as the opening one. By giving the model explicit permission to say the decision is sound, you remove its incentive to invent weak objections just to look thorough. A good red team makes your thinking harder to fool. It does not manufacture doubt to seem useful.
How Do You Calibrate the Challenge to the Decision?
Not every decision deserves a full assault. A routine team announcement does not need a pre-mortem that attacks the strongest argument; a restructure or an irreversible commitment does. The skill is matching the intensity of the challenge to the stakes of the decision, and telling the model which level you want.
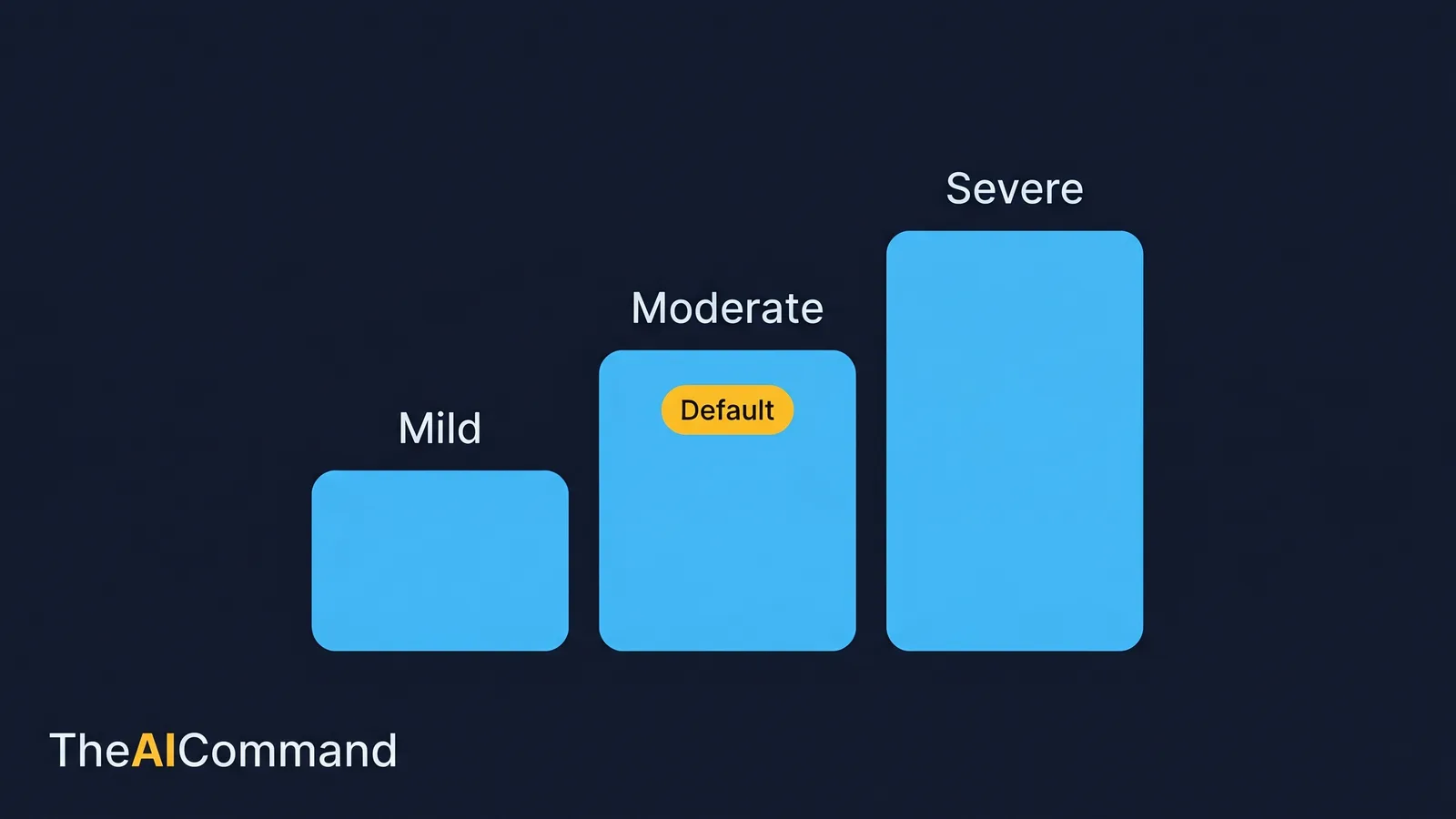
Three levels cover most leadership work.
- Mild challenge checks clarity. It asks whether the message is understandable, whether the logic is easy to follow, and whether anything is ambiguous. Use it for routine, reversible decisions.
- Moderate challenge tests assumptions and stakeholders. It probes the reasoning and rehearses how affected groups will react. This is the default setting for most management decisions.
- Severe challenge runs a full pre-mortem and attacks the strongest argument directly. It assumes the decision has already failed and works backwards to explain why. Reserve it for irreversible or high-consequence calls.
The contrast worth holding onto is between calibrated challenge and theatrical critique. Calibrated challenge is proportionate: three assumptions ranked by fragility, two stakeholder reactions ranked by likelihood, one message risk that could damage trust. Theatrical critique is dramatic and unbounded: a long list of objections with no ranking, no likelihood and no owner. The first improves a decision. The second performs the appearance of rigour. Tell the model which level you want, and you will get the first.
A Worked Example: Before and After
Theory is cheap, so here is the method on a real shape of problem. A people leader plans to announce a new productivity expectation after a difficult quarter. The draft is commercially sensible and direct. It is also, in its first form, a trust risk.
Here is the draft message as written.
The leader runs a narrative challenge and a stakeholder challenge across four perspectives: a high performer, an exhausted manager, a sceptical HR partner and a risk owner. The model returns a focused critique rather than a vague "this could be better". The critique table below is the output, converted straight into action.
The leader rewrites the message using the critique. The revised version keeps the decision intact. It does not soften the expectation. It changes how the expectation lands.
The AI did not soften the decision. It made the decision easier to communicate responsibly. That is the shape of value worth noticing: the work did not disappear, it moved. Less time was spent drafting in a vacuum, and more time was spent on what the message was actually allowed to mean.
Every Challenge Becomes an Action, or It Is Noise
A red-team session that produces interesting observations and no changes has failed, no matter how clever the observations were. The discipline that makes the method real is conversion: every challenge the model raises must become one of five actions, or it gets discarded.
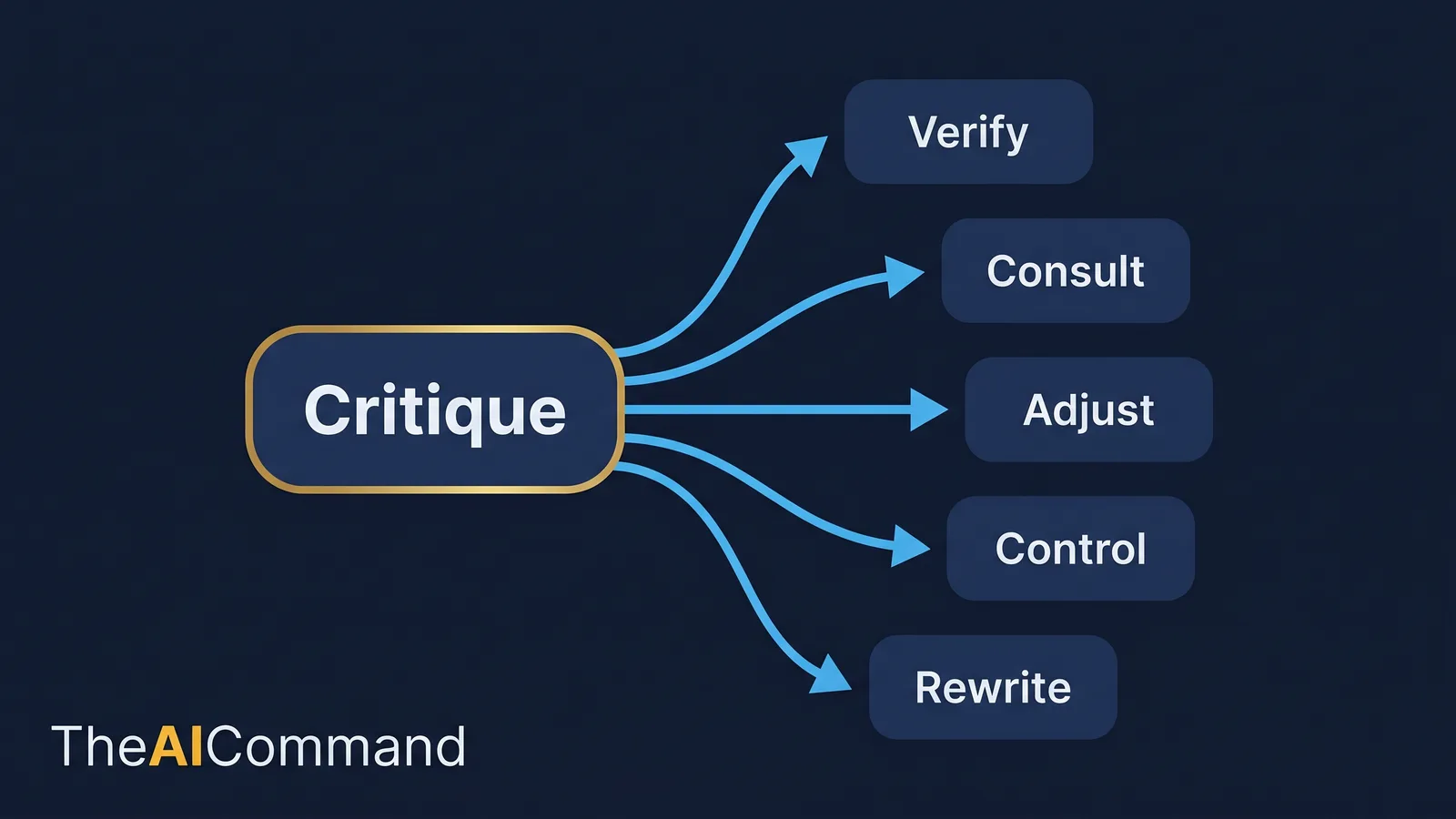
The five actions are deliberately small and concrete.
- Verify a piece of evidence that the decision is resting on.
- Consult a stakeholder whose reaction is uncertain or important.
- Adjust the decision itself in response to a genuine weakness.
- Control a risk by adding a mitigation, a check or an early-warning signal.
- Rewrite the communication so the message lands as intended.
If a critique does not map to one of those five, it may be interesting, but it is not operational, and it should not consume attention. To keep the session honest, record the conversions in a challenge log. The log is the difference between a red team that improves decisions and a conversation that changes nothing.
The closure note is the column leaders skip and should not. It records what actually happened to each challenge: accepted, rejected, evidence gathered, or plan changed. Over time the log becomes a record of which risks were real and which prompts produced noise, which is exactly the data needed to make the red team sharper next time.
The risk-weighting prompt below is what produces a usable register rather than a flat list.
Run the Challenge Across Three Time Horizons
Leaders usually ask AI for one critique and receive one time horizon, almost always the short term. That is how a decision can survive launch week and quietly fail a year later. Better red teaming separates the horizons so that short-term noise does not crowd out longer-term risk.
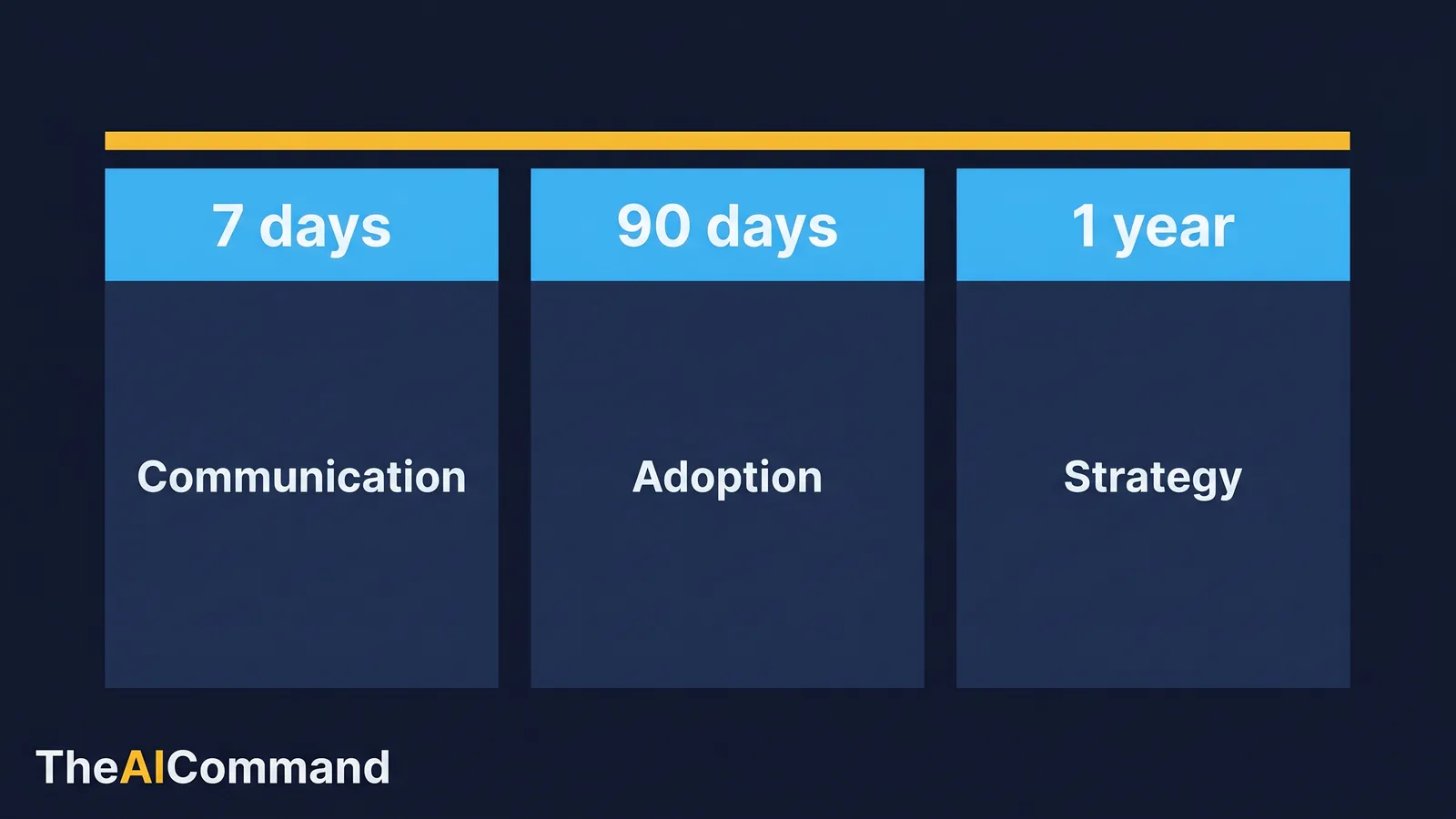
Three horizons cover most of what matters.
- Seven days. Tests communication, immediate confusion and operational readiness. Will people understand it, and can the team execute it on Monday?
- Ninety days. Tests adoption, behaviour change and resource strain. Does the decision stick once the announcement energy fades?
- One year. Tests strategy, capability and unintended incentives. Does the decision still look right when its second-order effects have played out?
The prompt below forces the model to keep the horizons distinct, which is the part it will not do on its own.
The downside challenge from the six-mode framework pairs naturally with this, because a pre-mortem is most useful when it is run against a specific horizon rather than "the future" in general.
Do Not Use AI to Launder Accountability
This is the principle that matters more than any prompt, so it gets its own name and its own place in the article rather than a buried footnote.
Do not use AI to launder accountability. A leader cannot run a decision through a model, point at the critique, and treat the matter as handled. "The AI challenged it" is not a defence, a sign-off, or a substitute for judgement. The model produces input. The leader produces the decision and owns the consequences.
The danger is subtle, because the laundering feels like rigour. A leader can generate a long, impressive-looking red-team report, file it, and proceed exactly as planned, now armoured with the appearance of due diligence. The hard human conversations, the ones where a senior colleague says "I think this is a mistake" to your face, never happen. The decision looks tested. It was only narrated.
A red team is legitimate cover only when it changes something or is consciously overruled with recorded reasoning. Rejecting a challenge after genuinely considering it is fine, and often correct, provided the reasoning is conscious and written down. What is not fine is using the artefact to manufacture an illusion that a decision has been challenged when the difficult parts were quietly skipped.
To keep the boundary visible rather than living in someone's head, write down what the model is not allowed to do. The judgement-boundary table makes that explicit, and the prompt after it generates a first draft of one.
The dividing line is consistent across high-stakes domains. In human resources, governance, risk and compliance, and workers compensation work, the model can prepare and rehearse, but qualified advisers and accountable leaders must be involved in anything with legal, safety or wellbeing consequences. The model is a junior analyst with a fast draft, not a decision-maker.
Building the Habit: A Practical Setup
The method is only as good as the habit around it. The setup below consolidates the moving parts into four practical commitments rather than a long checklist.
Build a small reusable prompt library. Create one prompt per common leadership moment: strategy choice, change communication, resourcing trade-off, performance expectation, risk acceptance and stakeholder escalation. Each prompt should specify the challenge mode, the expected output table and the human decision boundary. Reuse creates consistency, and consistency makes critiques comparable over time. The staged prompt below is a strong default, because it runs three modes in sequence and forces a human-decision pause after each.
Use AI to sharpen human challenge, not replace it. Run the red team before a human challenge session so colleagues react to a first list of weak points rather than a cold pitch. The conversation gets sharper because the assumptions, evidence gaps and stakeholder risks are already on the table. Then run it again after the session: feed the messy notes back and ask for unresolved questions, contradictions, action items and communication risks. AI prepares the ground and tidies the follow-up. People bring the context and the courage. Check the notes carefully where the discussion touched sensitive people, legal, risk or culture issues.
Hold a review with the artefact on screen. Treat each model output like a junior analyst draft: useful, quick, and incomplete until checked. Ask the decision owner to confirm what is known, what is assumed, what needs source checking and what must be escalated. Classify every correction as a source issue, a prompt issue, a process issue or a judgement issue. That classification improves the system, not just the single document.
Capture the lesson in the knowledge spine. When a critique or correction is worth keeping, record it in one durable place rather than letting it evaporate. A good lesson names the failure, the preferred behaviour, an example, and the prompt or template that needs updating. Over time this builds an organisational memory of how the team wants AI to behave. The goal is not to turn every manager into a prompt engineer. The goal is to make repeated decisions easier because the organisation remembers what it learned. This is the same knowledge spine described in the companion article on building a leadership decision system: a single, durable home for the reasoning behind decisions, not a scatter of notes across a dozen tools.
Measuring Whether the Red Team Helped
A red team should be evaluated, not just consumed. After a decision plays out, compare what actually happened against the warnings the model raised. Did the prompt identify the risk that occurred? Did it overstate risks that never mattered? Did it miss a stakeholder reaction entirely? The challenge log makes this easy, because the closure notes already record what each warning predicted.
This is where calibrated challenge proves its worth over theatrical critique once more. A theatrical critique generates so many objections that some will inevitably look prescient by chance, which teaches nothing. A calibrated, ranked critique can be scored honestly, because it committed to a small number of specific predictions. Treating critique quality as something to measure, rather than something to admire, is what turns a one-off habit into a capability that improves.
The natural pair to this article is the companion piece on leadership decision memos, which covers how to capture and structure the decision itself before you stress-test it. Read it alongside this one: the memo gives you something solid to challenge, and the six-mode red team gives the memo its teeth. See AI for leadership decision memos.
What to Do Next
Pick one upcoming decision that matters but is not yet irreversible. Write it down in a sentence, with your current leaning. Run the assumption challenge, then the stakeholder challenge, then the narrative challenge, in that order. Convert every surviving critique into one of the five actions and record it in a challenge log with an owner and a closure note. Use synthetic or low-sensitivity detail where you can. Then bring the sharpened list to a real human challenger.
Run it again on a slightly harder decision next week. That is how the habit compounds: not through one perfect prompt, but through a repeatable method that gets calibrated a little better each time. A good red team makes your thinking harder to fool. It does not tell you that you are wrong, and it never decides for you.
Bottom line
A red team makes your thinking harder to fool; it does not decide for you. Work in named challenge modes, calibrate the intensity to the stakes, and convert every surviving critique into a concrete action, because a session that changes nothing has failed. Never use the artefact to launder accountability: the model produces input, and the accountable leader produces the decision and owns the consequences.
Do this Monday:
- Pick one upcoming decision that matters but is not yet irreversible, and write it down in a sentence with your current leaning.
- Set the challenge level (mild, moderate or severe) to match the stakes before you prompt.
- Run the assumption, stakeholder and narrative challenges in that order, using synthetic or low-sensitivity detail.
- Convert every surviving critique into one of the five actions (verify, consult, adjust, control or rewrite) and log it with an owner and a closure note.
- Bring the sharpened list to a real human challenger rather than treating the report as the decision.
This article is general guidance and education only. It is not legal, compliance, human resources or financial advice, and it does not account for your organisation's policies, obligations or circumstances. AI outputs can be confident and wrong, and they tend to agree with the person prompting them. Before acting on any decision shaped by these methods, verify the facts against original sources and confirm the approach with the accountable people in your own organisation. Where a decision carries legal, safety, privacy or wellbeing consequences, involve a qualified adviser.
TheAICommand. Intelligence, At Your Command.
For more practical AI workflow ideas, follow TheAICommand on Instagram at @the_aicommand and X at @TheAICommand.
References
- Sharma, M. et al. (2023). Towards Understanding Sycophancy in Language Models. arXiv. https://arxiv.org/abs/2310.13548
- NIST. AI Risk Management Framework (Govern, Map, Measure, Manage). https://www.nist.gov/itl/ai-risk-management-framework
- Snowden, D. J. and Boone, M. E. (2007). A Leader's Framework for Decision Making. Harvard Business Review. https://hbr.org/2007/11/a-leaders-framework-for-decision-making
- Klein, G. (2007). Performing a Project Pre-mortem. Harvard Business Review. https://hbr.org/2007/09/performing-a-project-premortem
- Farnam Street. The Decision Journal. https://fs.blog/decision-journal/
- Atlassian. Team Playbook. https://www.atlassian.com/team-playbook
- Nielsen Norman Group. AI as a UX Assistant. https://www.nngroup.com/articles/ai-roles-ux/
TheAICommand. Intelligence, At Your Command.


