
The strongest use of AI in leadership is not asking the model what to do. It is asking the model to prepare the surface a leader thinks on: the question, the options, the assumptions, the evidence, the trade-offs, the people affected, the risks and the trigger to revisit. AI prepares the thinking. The leader decides. A decision memo is where that line stays clean, because the memo forces every claim into the open before anyone signs up to it.
General guidance and education only. This is not legal, financial or professional advice. Verify any approach with the relevant people in your own organisation before relying on it.*
Most poor decisions do not fail for lack of information. They fail because the question was never framed, an assumption nobody checked turned out to be wrong, soft opinion was dressed as hard evidence, or the decision was made late on a Friday with no agreed signal for when to look at it again. Those are not intelligence problems. They are structure problems. AI is unusually good at structure, which is precisely why a decision memo is the right place to point it.
This article sets out a repeatable method. It treats AI as a structure engine, a critique partner and a drafting accelerator, while the source evidence, the professional judgement and the accountable approval stay with named people. It pairs with AI as a red team for leaders: this piece structures the decision, the red-team piece stress-tests it before commitment.
Why does structure beat more information?
Leaders are rarely short of inputs. They are short of clear frames, validated assumptions and honest evidence. Three named practices point at the same discipline, from three different angles.
The first is the decision journal, popularised by Farnam Street, which asks a decision-maker to record the situation, the expected outcome and the reasoning at the moment of deciding, so the quality of the thinking can be reviewed later rather than judged only by the result [1]. The second is structured team facilitation, such as the plays in the Atlassian Team Playbook, which exist to make hidden disagreement and unstated assumptions visible before a group commits [2]. The third is Cynefin, the decision-making framework set out by David Snowden and Mary Boone in Harvard Business Review, which argues that leaders must first work out what kind of situation they are in, because clear, complicated, complex and chaotic situations each call for a different response [3].
All three share one idea. Better decisions come from clearer framing and more honest reflection, not from more data. AI can accelerate that framing. It can turn messy notes into a structured memo in minutes, surface the assumptions buried in the prose, and make the trade-offs explicit. What it cannot do is carry the accountability. That distinction is the whole method.
Cynefin is worth holding onto as you read. Snowden and Boone's point is that the response should match the situation [3]. In a clear, well-understood situation, the memo can be short and AI's role is mostly drafting. In a complicated situation, where the answer exists but needs analysis, the memo earns its keep by forcing options and evidence into the open. In a complex situation, where cause and effect are only visible in hindsight, the memo should lean hard on assumptions, pre-mortems and review triggers, because the team will learn by acting. AI can draft for any of these, but it cannot tell a leader which one they are in. Reading the situation is a leadership act.
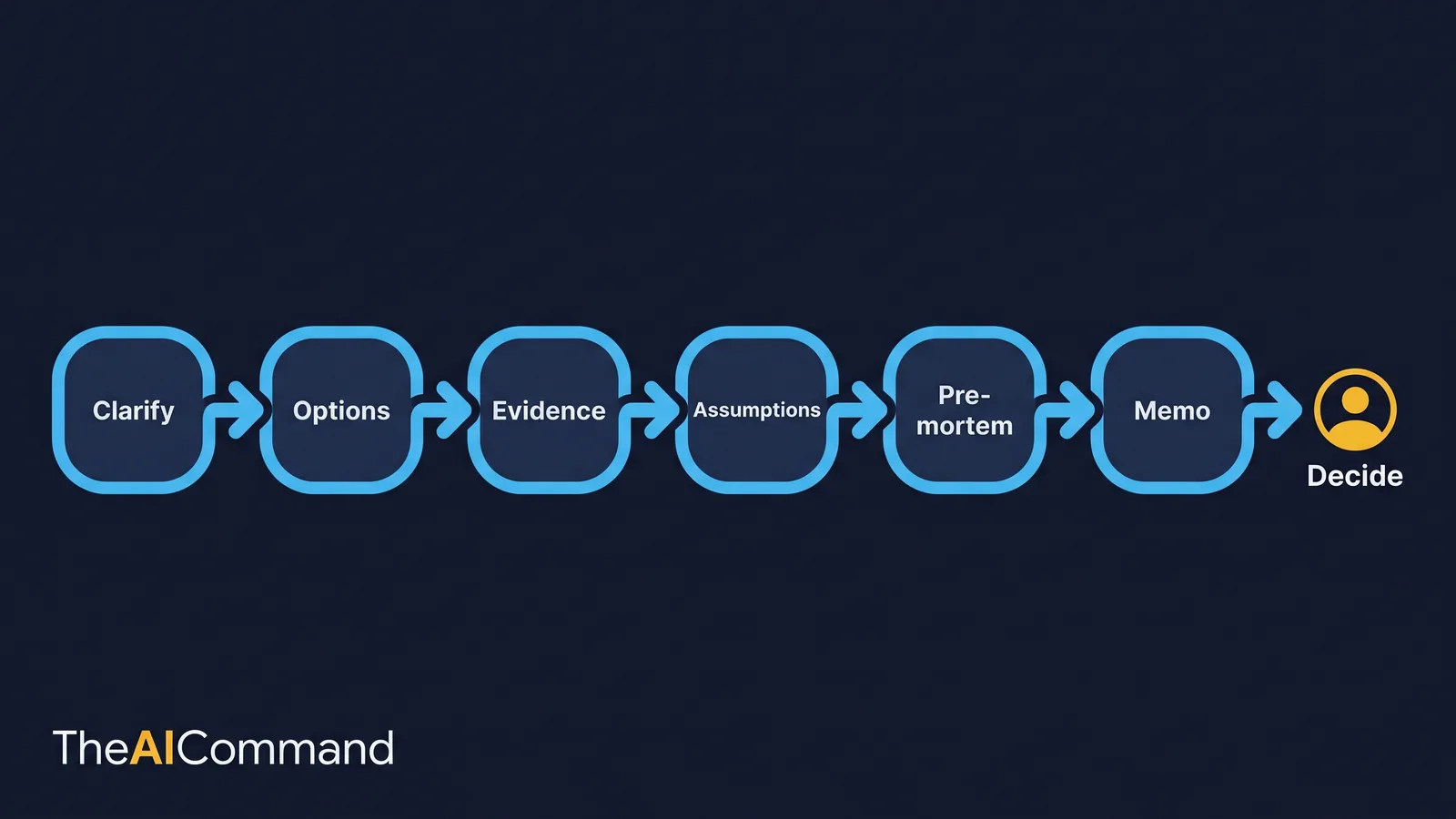
The method, end to end
The sequence below is deliberate. Each step narrows the task before the next one builds on it. Skipping to the final draft is the most common way to get a beautiful memo that quietly buries weak evidence in smooth prose.
1. Clarify the decision question. A vague question produces a vague memo. A good question names the decision, the timing, the owner and the consequence. "Should we change our compliance model" is a topic. "Should compliance task X be centralised into a single team by 1 September, owned by the Head of Operations, given current headcount" is a decision.
2. List real options, separate from the preference. AI can generate viable options, but the leader must state the current leaning and the assumptions behind it. Naming the preference up front reduces the risk that the model simply rationalises the path the leader already wanted.
3. Map the evidence by quality. Not all evidence is equal. The memo should separate observed facts from estimates, stakeholder views, expert judgement, hard constraints and outright unknowns. This is also where AI's own failure modes bite, which the evidence section addresses directly.
4. Test the assumptions. Identify what has to be true for the preferred option to work, then rank those assumptions by impact and by how well they are evidenced. The high-impact, low-evidence assumptions are the ones to chase before deciding.
5. Run a pre-mortem. Assume the decision has failed, then work backwards to the most plausible reasons. Gary Klein set out this technique in Harvard Business Review, arguing that imagining a failure that has already happened surfaces risks that a standard "what could go wrong" question does not [4]. It works because people are more candid about a failure they are describing than a risk they are predicting.
6. Draft the memo, then name the review trigger. A decision without a review trigger becomes a memory test. The memo should specify the signal that would cause the leader to revisit the call, and who watches for it.
A worked memo: centralise or keep embedded
Method is easier to trust when you can see it filled in. Consider a Head of Operations deciding whether to pull a small compliance task out of the business teams and into one central team, or leave it embedded where it sits. The usual meeting would produce opinions, two strong anecdotes and a rushed answer. A decision memo produces something a board could read in two minutes.
Here is that memo, completed end to end.
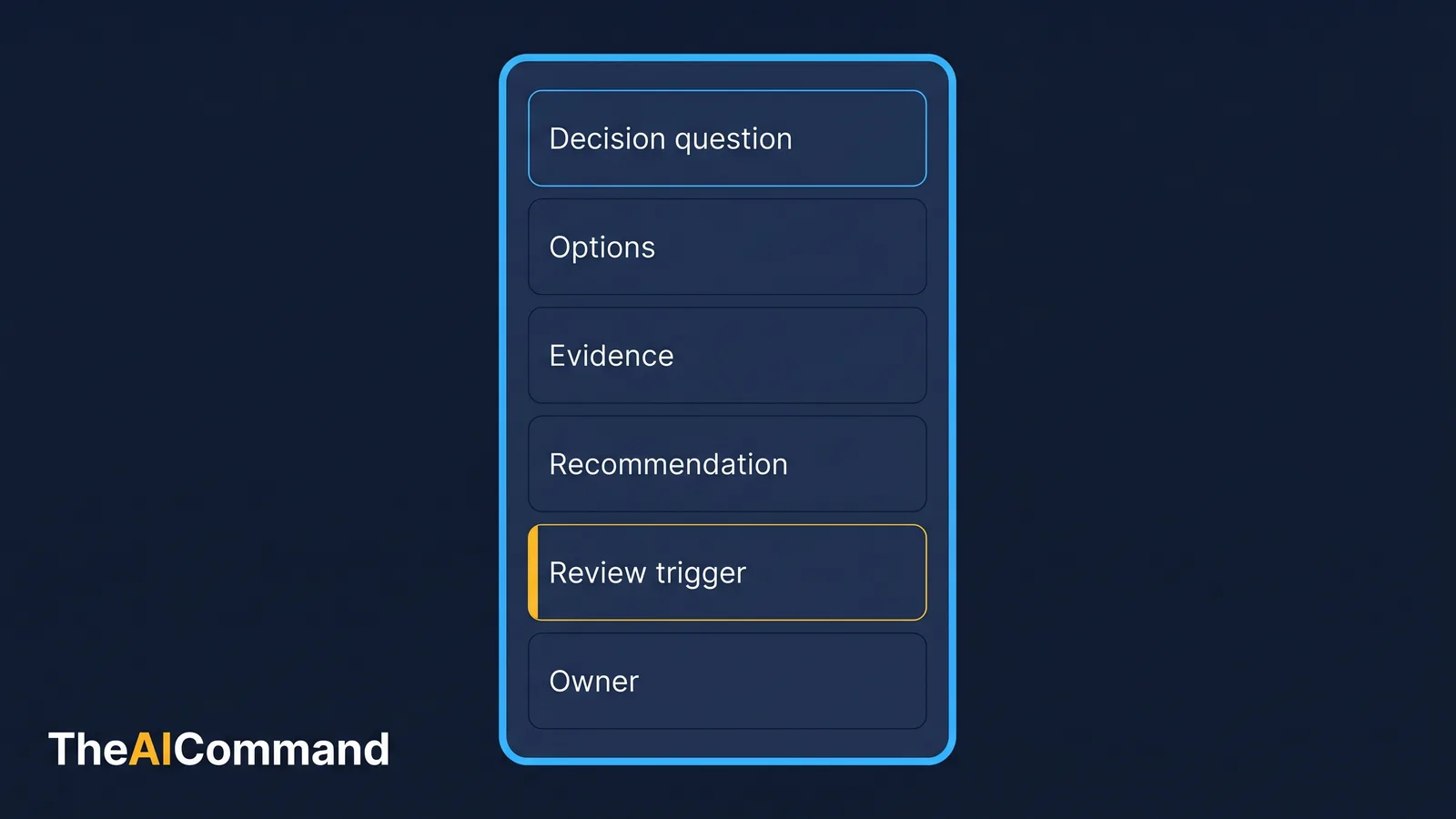
Decision question. Should compliance task X be centralised into a single team by 1 September 2026, owned by the Head of Operations, or remain embedded in the four business teams that perform it today? The trigger for deciding now is a recurring quality variance across teams and an upcoming audit.
>
Cynefin read. Complicated, not complex. The task is well understood and the variance has analysable causes. This means the memo can rely on evidence and analysis rather than pure experimentation, but the staffing question below pushes one corner of it into the complex zone.
>
Options. 1. Centralise into one dedicated team. Consistency improves, business context may be lost, one team becomes a single point of failure. 2. Keep embedded, add a shared standard and a quarterly peer review. Lower disruption, slower to lift quality, relies on local discipline. 3. Hybrid: a small central standards owner, delivery stays embedded. Captures consistency without removing local context, adds a coordination cost.
>
Evidence, by type. Observed fact: quality variance between teams is real and is in the audit logs. Expert judgement: the quality lead believes a single standard would close most of the gap. Stakeholder view: two business leads prefer to keep the task; they value local control. Constraint: the audit lands in October and cannot move. Unknown: whether one central team can be staffed from existing headcount without backfilling the business teams.
>
Assumptions, ranked. High impact, low evidence: that centralisation can be staffed from current headcount. This is the load-bearing assumption and nobody has validated it. High impact, well evidenced: that a single standard reduces variance. Lower impact: that business leads will adopt a shared standard if delivery stays with them.
>
Pre-mortem. It is March 2027 and the change has failed. The most plausible story: the central team was understaffed because the headcount assumption was wrong, the backlog grew, the October audit found gaps, and the business teams had already lost the muscle to do the work. Early warning signal: central team backlog rising in the first month. Prevention: confirm the staffing model before committing.
>
Recommendation. Defer the centralise decision by one week. Validate the staffing assumption first by modelling the central team workload against available headcount. If the assumption holds, proceed with option 3, the hybrid, as the lower-risk route to consistency. If it does not hold, option 2 with a hard standard becomes the recommendation.
>
Review trigger. Revisit if central team backlog exceeds two weeks of work at any point before the October audit, or if the staffing model shows a shortfall above one full-time equivalent.
>
Owner. Head of Operations owns the decision and the consequence. The quality lead owns the staffing model. Review date: one week from today.
The point of the worked example is what the memo changed. Before it, the preferred option was quiet centralisation. After it, the leader could see the whole case rested on a staffing assumption nobody had checked. The decision was deferred a week, the assumption was tested, and a Friday-afternoon instinct became a Monday-morning question with an owner. AI did not make the decision. It made the weak assumption impossible to ignore before the leader signed up to it.
Who actually owns the decision?
A memo is only as good as the clarity about who actually holds the decision right. This is where decision-rights models earn their place. RAPID, developed by Bain, separates the people who Recommend, Agree, perform the Input, have the Decide right and must Perform the result, so that a decision does not stall in committee or get quietly captured by the loudest voice. RACI does a similar job for tasks, naming who is Responsible, Accountable, Consulted and Informed.
For a decision memo, two roles matter most. One person holds the Decide right and owns the consequence. That cannot be shared with a model, and it should not be diffused across a meeting. Others Recommend, provide Input or must Agree, and the memo should name them. AI can draft the stakeholder map and flag who is missing, but assigning the decision right is a leadership act, not a drafting one.
A light operating structure keeps the method honest across many memos. Name three hats, even if one person wears several on a small team. The domain owner confirms what the content means. The workflow owner maintains the prompts, the template and the tool behaviour. The reviewer checks that outputs are grounded, proportionate and safe to use. When something goes wrong later, those three hats make it clear where the fix belongs.
Which assumptions are worth slowing down for?
Assumptions are where confident memos go to die. The discipline is to make every load-bearing assumption explicit, then plot it on two axes: how much it matters to the decision, and how well it is evidenced.
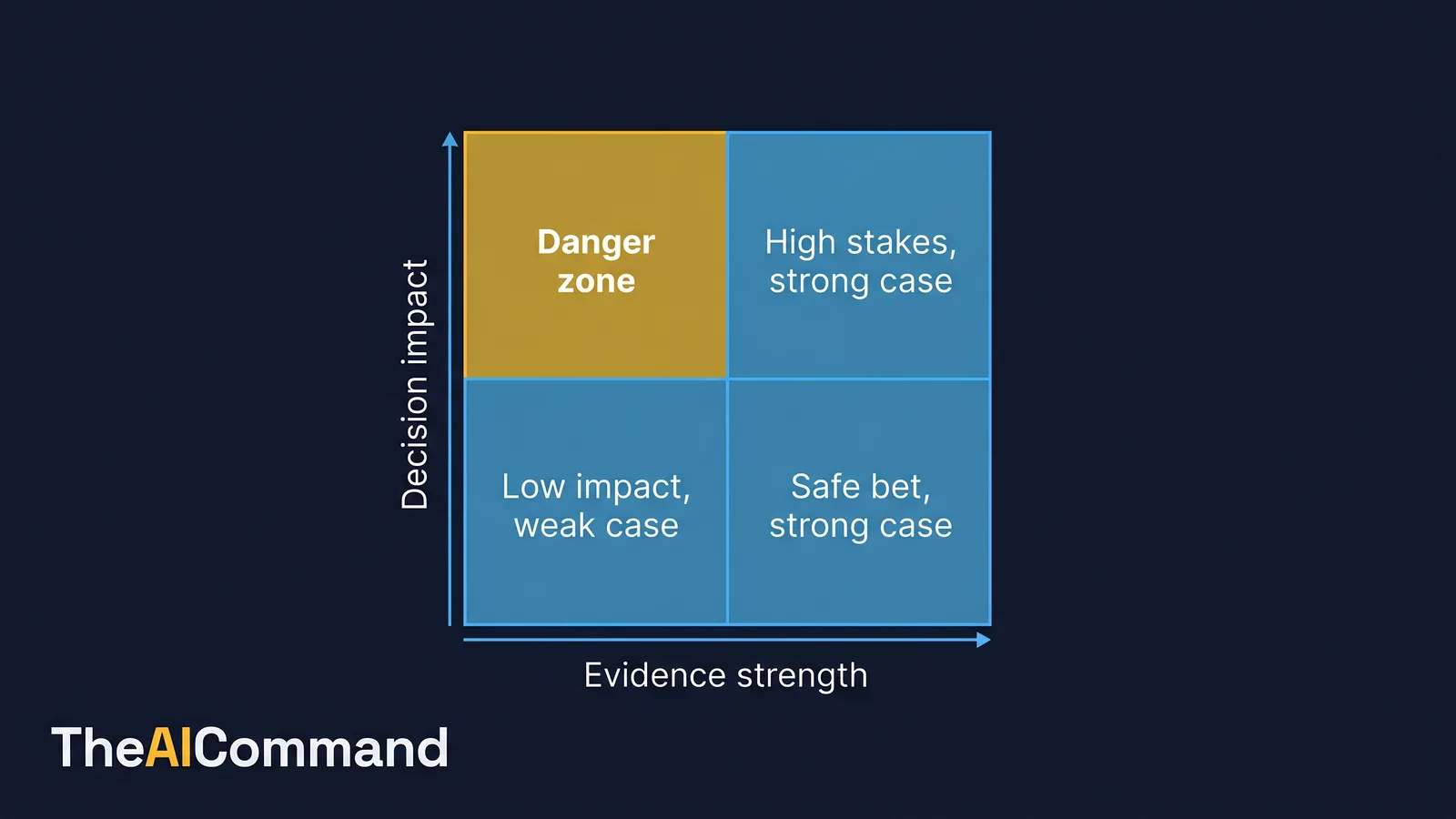
The danger zone is the top corner: assumptions that carry the decision but rest on almost nothing. In the worked example, the staffing assumption sat squarely there. A high-impact, well-evidenced assumption is fine to proceed on. A low-impact assumption can be noted and left. The high-impact, low-evidence assumptions are the only ones worth slowing down for, and the smallest evidence-gathering action that could validate or weaken each one is usually a one-week task, not a one-month project.
This is also the step where AI's own behaviour needs watching, which the next section covers, because a model asked to rank assumptions will sometimes agree with the framing it was handed rather than challenge it.
Evidence discipline, including the AI's own failures
Source discipline is the quiet difference between impressive AI output and professional AI output. Before asking for a polished answer, give the model the source boundary, tell it what it may not infer, require uncertainty markers, and ask it to point each claim back to the evidence. When the source is incomplete, the correct output is a gap list, not a confident paragraph.
A simple ladder keeps evidence honest. Rank every input from observed fact at the top, down through expert judgement, stakeholder opinion, forecast and benchmark, to constraint and finally unknown. Soft signals near the bottom of the ladder must not be presented as hard proof near the top. Leaders can still use judgement, but they should know when judgement is filling an evidence gap rather than reading evidence.
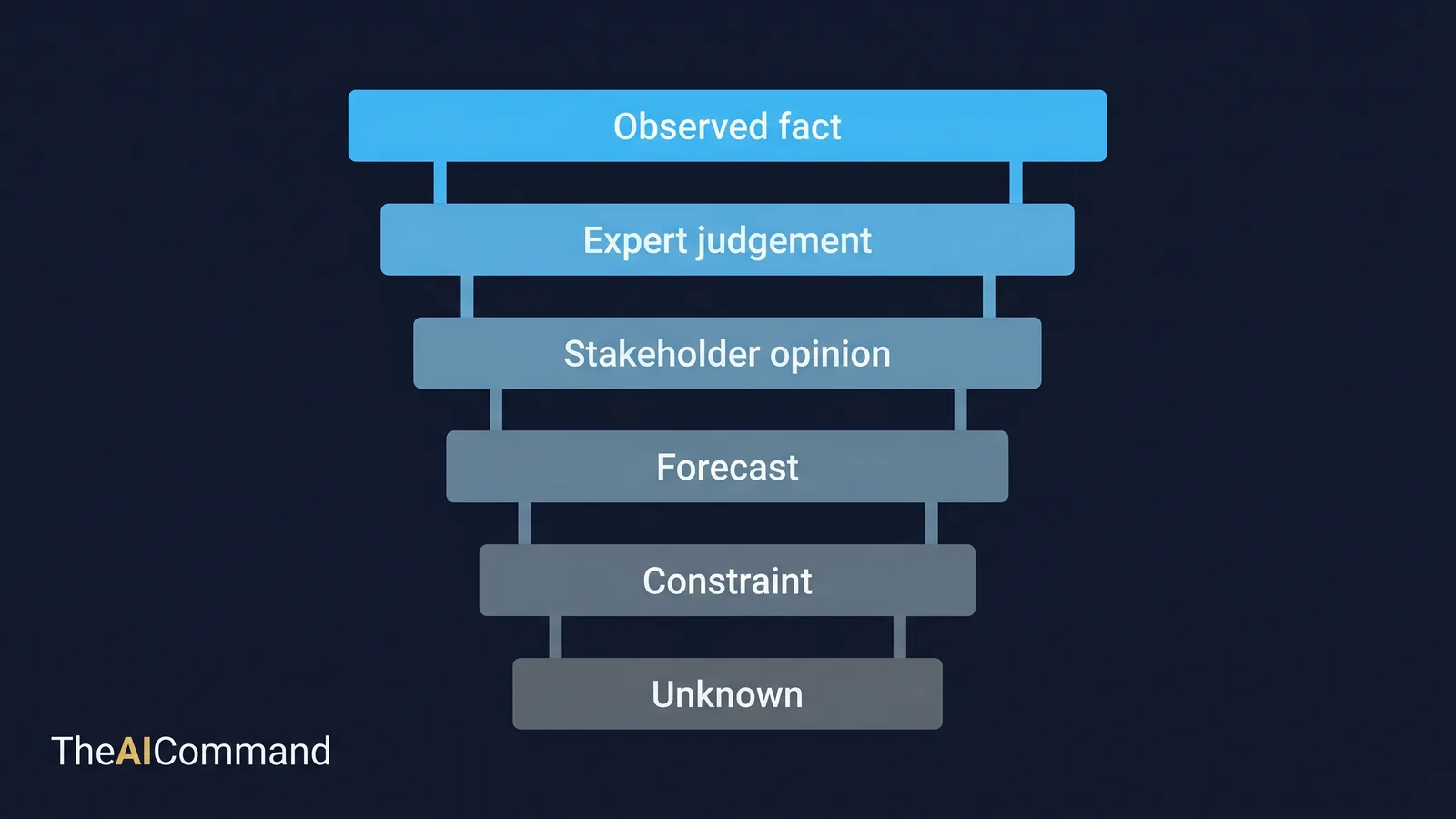
The evidence types map cleanly onto how each one should be treated in the memo.
There is one more class of evidence failure to guard against, and it comes from the model itself. AI systems are prone to sycophancy, the tendency to agree with the user's framing and tell them what they appear to want to hear. A model handed a preferred option and asked to assess it will sometimes assemble a flattering case rather than a candid one, which is the reason to make the model disagree with you before you decide. AI systems also fabricate. They can produce a confident citation, statistic or quote that does not exist. Nielsen Norman Group's research on AI as a UX assistant makes the same point from the practitioner side: AI is reliable as a supporting tool that a professional reviews and validates, not as an unsupervised source of truth [5].
The practical defence is a hard rule in the workflow: verify AI-supplied evidence before it enters the memo. Any fact, figure, citation or quote the model introduces is treated as unconfirmed until a person has checked it against the source. If it cannot be traced to a real source, it does not go in the recommendation. It goes in the gap list. This single step prevents the most damaging memo failure, which is a polished recommendation built partly on evidence the model invented.
Building the one-page memo
A one-page memo can outperform a thirty-slide deck when it names the question, the options, the evidence, the assumptions, the risks and the review trigger. AI builds the first structured surface fast. The leader chooses what matters and what is tolerable.
The table below is the working artefact: what AI can do for each section, what the leader must supply, and the quality check that says the section is done. Copy it into a planning document and adapt the fields.
For larger decisions, run two pages. Page one carries the recommendation, options, evidence and trade-offs. Page two carries the assumptions, pre-mortem, stakeholder impacts and review trigger. The format keeps the decision readable while preserving the harder thinking, and the leader decides which caveats belong in the live discussion.
The review trigger deserves more than a line. A trigger can be a date, a metric, an event or a risk signal, and the strongest memos name which one. The table below shows the four kinds in practice.
A named trigger gives AI a future role too. When the trigger fires, the model can compare actual outcomes against the assumptions recorded at the time, which is exactly the loop a decision journal is built to support [1].
The prompt stack
The prompts below follow the method. The first narrows the task. The middle ones generate and test the artefact. The last creates the memo and the evidence map. Keep them runnable and adapt the wording to the decision.
Clarify the question
Generate the options
Audit the assumptions
Run the pre-mortem
Map the evidence and verify it
Draft the one-page memo
Failure modes to design against
A handful of failures recur, and AI can make each of them sound polished, so the review checklist must look for them directly.
- Turning uncertainty into confidence. A good memo makes uncertainty easier to see, not harder. If the prose reads as settled and the evidence is thin, the memo is lying with tone.
- Skipping the decision owner. Shared thinking is useful. Accountability cannot be crowdsourced to a model or to a meeting. One named person holds the Decide right.
- Using the memo to justify a fixed answer. Leaders need critique before commitment. A memo with one viable option dressed as three is theatre.
- Ignoring who is affected. A technically correct decision can still fail socially. Name the stakeholders and the adoption risk.
- Trusting AI-supplied evidence. Sycophancy and fabrication are real. Every fact the model adds is unconfirmed until a person checks it.
A clean governance test sits behind all of these. Ask what the model is not allowed to do, and make the answer visible in the workflow, the prompt, the template and the review step. If that boundary lives only in someone's head, it will be missed under time pressure, which is exactly when it matters most.
The operating rhythm
Method becomes capability when it is run on a rhythm rather than improvised each time.
- Build a standard decision memo template for recurring leadership decisions.
- Use AI first to clarify the question, never to recommend the answer.
- Run the assumption audit and the pre-mortem before drafting the recommendation.
- Verify every AI-supplied fact, figure and citation against a real source.
- Ask at least one human to challenge the memo before the decision, ideally as a red team.
- Record the decision, the reasoning and the review trigger in a decision journal [1].
- Return on the trigger and capture the lesson for the next memo.
Run the decision meeting with the memo on screen as the thinking surface. Start with the question, then the assumptions and trade-offs, before anyone argues about wording. Ask which assumption each person would test first if they had one extra week, and capture the answer. That is a more useful meeting than a debate over phrasing.
Store strong memos in a leadership knowledge base once sensitive material is removed. Capture a consistent set of fields each time: decision type, date, owner, option chosen, options rejected, the top assumption, the review trigger and the eventual outcome. Over time the library gives leaders worked examples of good framing, recurring assumptions and common failure modes, and AI can compare a new decision against past patterns while the leader keeps responsibility for context. Consistent fields are what make the library searchable later.
A final test keeps the whole method honest. If the memo cannot be summarised in one sentence, the decision is not yet clear, so rewrite the question before rewriting the recommendation. And if a capable colleague could not pick up the artefact next week and use it without a ten-minute explanation, the labels, fields or examples need work. AI output should reduce handover friction, not create a private maze.
Where to start
Pick one recurring decision, one memo template and one review loop. Build the smallest useful version first, using low-sensitivity information. Run the prompt stack in order. Capture what failed, and turn each correction into a durable instruction, a stronger template field or a lesson in the journal. Then take a slightly harder decision next time. Capability compounds through repetition, not through a single clever prompt. Once the memo is built, the next move is to break it on purpose, which is the work of AI as a red team for leaders.
Bottom line
Use AI to prepare the decision memo, not to make the decision. Let it sharpen the question, generate options, sort evidence by quality, test the assumptions and run the pre-mortem, while one named person keeps the judgement, the decision right and the consequence. The weak assumption you can no longer ignore is the memo doing its job.
Do this Monday:
- Rewrite one recurring decision as a specific, time-bound question that names the owner.
- List real options first, then state your current leaning so the model cannot just rationalise it.
- Rank your load-bearing assumptions by impact and by evidence, and chase the high-impact, low-evidence ones.
- Run a pre-mortem, then name the review trigger and who watches for it.
- Verify every AI-supplied fact, figure or citation against a real source before it enters the memo.
This article is general guidance and education only. It is not legal, financial, governance or professional advice, and it does not account for the circumstances of any particular organisation. Decision-rights models, governance frameworks and record-keeping obligations differ between organisations and jurisdictions. AI tools can produce confident but incorrect or fabricated output, so any AI-assisted memo should be reviewed and validated by a qualified person before it informs a real decision. Verify any approach described here with the relevant people in your own organisation, including risk, compliance and legal where the decision warrants it. The human who holds the decision right owns the decision and its consequences.*
TheAICommand. Intelligence, At Your Command.
For more practical AI workflow ideas, follow TheAICommand on Instagram at @the_aicommand and X at @TheAICommand.
References
- Farnam Street. Decision Journal. https://fs.blog/decision-journal/
- Atlassian. Team Playbook. https://www.atlassian.com/team-playbook
- Snowden, D. J. and Boone, M. E. A Leader's Framework for Decision Making. Harvard Business Review, November 2007. https://hbr.org/2007/11/a-leaders-framework-for-decision-making
- Klein, G. Performing a Project Premortem. Harvard Business Review, September 2007. https://hbr.org/2007/09/performing-a-project-premortem
- Nielsen Norman Group. AI as a UX Assistant. https://www.nngroup.com/articles/ai-roles-ux/
TheAICommand. Intelligence, At Your Command.


