
Your privacy policy is about to become an AI disclosure document.
From 10 December 2026, Australian Privacy Principle 1 changes. APP entities that use personal information in automated decision-making will have to describe that use in their privacy policy. The Office of the Australian Information Commissioner states the obligation plainly: "From 10 December 2026, APP entities that use personal information in ADM with the potential to affect rights or interests will be required to provide information in their privacy policies about the kinds of personal information used and the kinds of decisions made using ADM." The OAIC ran a public consultation on its guidance that closed on 15 June 2026, so the supervisory expectations are being written now.
For most organisations this reads as a documentation task. For Australian banks, insurers and credit providers it is larger than that, because automated decisions about people are not a future capability. They are the engine room. Credit scoring, fraud detection, transaction monitoring, collections prioritisation, claims triage and pricing already run on models. The new rule does not ask whether you use them. It asks you to say so, in public, in a way the regulator can test.
What the rule actually requires
The obligation sits in two new clauses, APP 1.7 and APP 1.8, inserted by the Privacy and Other Legislation Amendment Act 2024. The trigger is defined with care. As Johnson Winter Slattery summarises the drafting, an entity is caught where it has "arranged for a computer program to make, or do a thing that is substantially and directly related to making, a decision" that uses personal information and "could reasonably be expected to significantly affect the individual's rights or interests."
Two phrases do the heavy lifting. The first is "substantially and directly related to making" a decision. That reaches past the system that issues the final answer to the systems that shape it. A model that scores an applicant's risk, ranks a file for review or flags a transaction is doing something substantially and directly related to a decision, even if a human clicks approve at the end. The second phrase is "significantly affect the individual's rights or interests." A marketing segmentation that nudges which email someone receives is unlikely to qualify. A decision that declines credit, prices a premium, freezes an account or refers a claim almost certainly does.

When the trigger is met, APP 1.8 sets out what the privacy policy must contain. The entity must describe three things: "the kinds of personal information used in the operation of such computer programs", "the kinds of such decisions made solely by the operation of such computer programs", and "the kinds of such decisions for which a thing, that is substantially and directly related to making the decision, is done by the operation of such computer programs". Read that last clause twice. It draws an explicit line between fully automated decisions and decisions where a machine does part of the work and a person finishes it. Both must be disclosed.
The distinction that keeps the scope sane
It is easy to read this rule as a demand for algorithmic explainability, and to panic accordingly. It is not. The obligation is about transparency at the level of kinds, not individual decisions. You describe the categories of personal information your automated systems use and the categories of decisions they make or shape. You are not required to publish model logic, expose feature weights or explain why a particular customer was declined. That heavier territory is being debated elsewhere, but it is not what commences in December.
That distinction matters because it tells you how much work is actually in front of you, and where it sits. The task is to know your systems well enough to describe them honestly, then to write that description into a public document. The first half is governance. The second half is drafting. The drafting is the easy part.
Why financial services feels this first
Three features of regulated financial services make this obligation land harder than it will for a typical APP entity.
The decisions are consequential by definition. Credit, insurance and banking decisions affect rights and interests almost by nature, so the "significantly affect" threshold is cleared routinely rather than rarely. The question for a bank is not whether the rule applies, but to how many systems.
The systems are layered and old. Automated decisioning in financial services is rarely one clean model. It is a stack of rules engines, scorecards, vendor services and, increasingly, machine learning models, accreted over years and owned by different teams. Describing "the kinds of personal information used" across that stack requires an inventory many organisations have never assembled in one place.
The regulator has signalled it will look. The OAIC's new enforcement powers to issue infringement notices and compliance notices apply to a failure to maintain a privacy policy that meets the APP 1.7 requirements, and civil penalty exposure sits behind that, as MinterEllison notes in its analysis of the OAIC's posture. The OAIC has flagged privacy policies in high-risk sectors as a focus. Financial services is a high-risk sector on any reading.
The human-in-the-loop trap
The most common misreading is that a human approval step takes a system out of scope. It does not. APP 1.8 expressly covers decisions where a machine does something substantially and directly related to making the decision and a person finishes it. If a credit officer approves dozens of declines an hour because a model ranked and recommended them, the model is substantially shaping those decisions. They are in scope. The test is not who clicks the button. It is whether the machine did work that materially shaped the outcome.
This catches a pattern regulated firms rely on. Many AI deployments in financial services are deliberately kept human in the loop precisely to manage risk, and that design choice is sound. It does not move the decision out of the disclosure obligation. Take a simple worked example. A general insurer runs incoming claims through a model that scores fraud likelihood and routes high scores to a special investigations queue. A person decides every referral. The model still substantially shapes which claimants get investigated, using their personal information, in a way that affects their interests. That arrangement belongs in the privacy policy, described at the level of kinds.
The same logic reaches your vendors. If a third-party service scores, flags or prioritises people using personal information you supply, you have arranged for a computer program to shape a decision, and the disclosure is yours to make. Map vendor systems with the same lens as your own, and check that your contracts give you enough visibility to describe them honestly. A disclosure that quietly omits the decisions made by outsourced systems is not a complete disclosure.
The readiness work, in four moves
The good news is that the work overlaps almost entirely with AI governance you should already be doing. If you have built an AI use case register, you are most of the way there. If you have not, this obligation is the forcing function.
Inventory the automated decisions. Find every system that makes or substantially shapes a decision about a person using personal information. Go past the systems labelled "AI". The scorecard built in 2014 counts. The vendor fraud service counts. The collections prioritisation logic counts. Capture the system, the decision it touches, the personal information it uses and whether the decision is fully automated or human-finished.
Classify by impact. For each, ask whether the decision could reasonably be expected to significantly affect the person's rights or interests. Decline, price, restrict, refer, prioritise: these are the verbs that put a system in scope. This is a judgement, so record the reasoning, because the reasoning is what you will defend.
Draft the disclosure. Translate the in-scope inventory into the three APP 1.8 categories: kinds of personal information used, kinds of fully automated decisions, kinds of decisions a machine substantially shapes. Write at the level of kinds, in plain language a customer can follow. This is the part that takes an afternoon once the inventory exists.
Evidence it. Keep the inventory, the impact assessments and the version history of the policy as a governance record. When the OAIC asks how you decided what to disclose, the answer is a register and a dated decision trail, not a memory.
Sequence the work backwards from December and the inventory is the long pole, not the drafting. A team can rewrite a privacy policy in a week once it knows what to say. Finding every automated decision across a layered system estate, agreeing which ones meet the significant-effect threshold, and documenting the reasoning takes months in a large organisation, and it needs input from product, technology, model risk and the lines of business, not just legal. Start the inventory now, run the impact classification in parallel, and leave the policy edit for last. A team that opens the policy first, before it has mapped its systems, will write a disclosure it cannot stand behind.
Context callout. Australia is following a path the European Union set with the GDPR's provisions on automated decision-making, but the Australian rule is narrower and more practical. It is a transparency obligation about kinds of decisions, not a general right to human review of every automated decision or a full explainability mandate. Reading it as the GDPR's Article 22 will lead you to over-scope the work. Reading it as a privacy-policy disclosure backed by real enforcement powers will get the scope right.
Build the register and the disclosure in an AI project
The four moves above are governance work, but a meaningful slice of them, the structuring, the classification logic and the first-draft drafting, can be accelerated with a general-purpose model, as long as you build a dedicated project space and never feed it anything live. A project space gives the model standing context (your privacy policy, your system inventory format, the OAIC's published guidance) so that every prompt runs against the same governance frame instead of starting cold.
A standing note on data, before any of this. Never paste real personal, claim, health or incident data into a model that is not an approved enterprise instance. The inputs below use a de-identified estate list: system names and decision descriptions only, with placeholder tokens like [SYSTEMID], [TEAM], [VENDOR] and [DATE] standing in for anything that could identify a person or a confidential arrangement. The model is a drafting and structuring aid. It produces a register skeleton and disclosure language. It does not decide what is in scope. You do.
Set up a ChatGPT Project (or a Claude Project) called something like "ADM Register and APP 1.8 Disclosure". Paste the following into the project's custom instructions or project description so the context holds across every chat in the project.
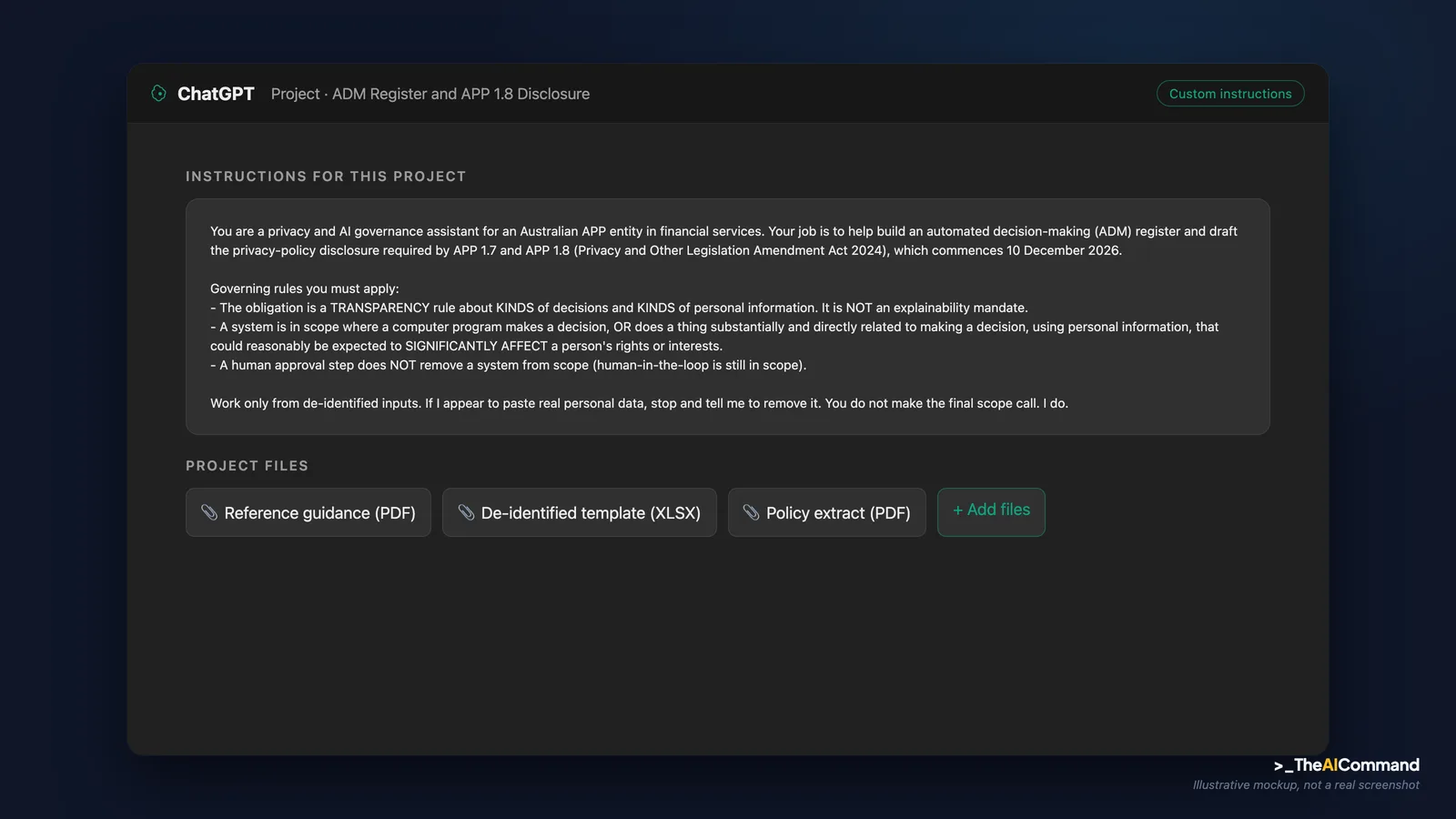
Files to upload to the project. Three documents give the model enough context to be useful without ever touching live data:
- Your current privacy policy (the public document you will be amending), so drafts match your existing voice and structure.
- A de-identified system inventory or estate list: system names, owning teams, a one-line description of what each does, and whether a decision is fully automated or human-finished. Strip anything confidential to placeholder tokens.
- The OAIC's published ADM transparency guidance and the relevant extract of APP 1, so the model classifies against the actual test rather than its training-data memory of overseas rules.
Prompt library
Each of these is a ready-to-run prompt for the project above. They follow the four moves: inventory, classify, draft, evidence. Keep using de-identified inputs only.
1. Inventory the ADM systems from a de-identified estate list.
2. Classify each system by impact on rights.
3. Draft the APP 1.8 disclosure language.
4. Produce register evidence for the governance record.
Worked example: a general insurer's fraud-scoring model
Walk one system end to end so the project and prompts have something to stand on. The scenario is a general insurer, de-identified throughout, but the shape is recognisable to any regulated Australian enterprise running a referral model.
The system. [INSURER] runs incoming claims through a fraud-scoring model, [SYSTEMID], owned by [TEAM]. The model scores each claim for fraud likelihood using the claimant's personal information and routes high scores to a special investigations queue. A human investigator decides every referral. No claim is declined by the model. On the surface, a privacy lead might wave it through as "human-decided, out of scope".
The setup. The privacy lead opens the ADM Register project, confirms the custom instructions and uploaded files are in place, and adds one de-identified row to the estate list before running Prompt 1:
The prompt and the illustrative output. Running Prompt 1 over that row, the model returns an inventory row and reasoning along these lines:
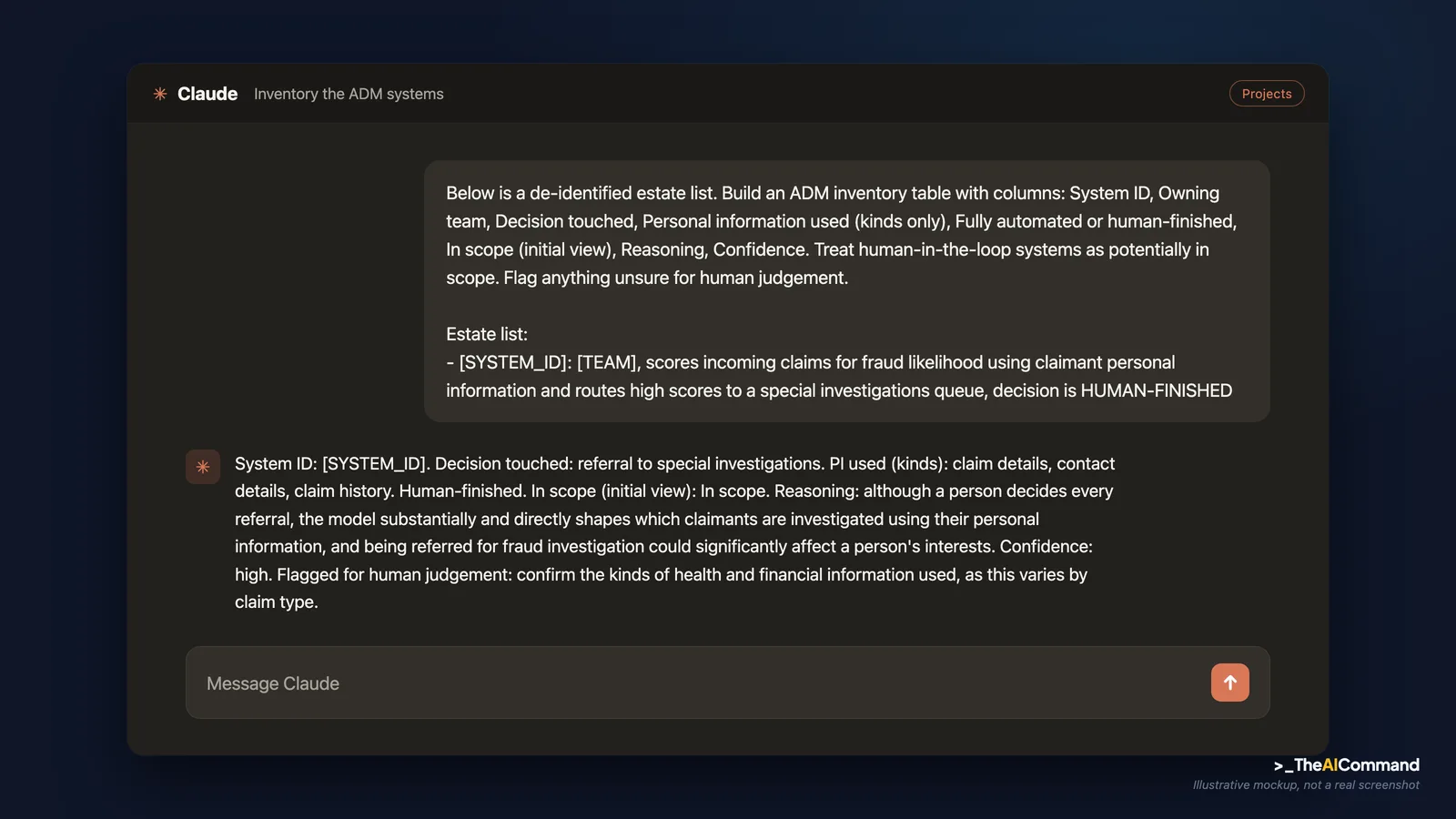
The model's illustrative output reads:
System ID: [SYSTEMID]. Owning team: [TEAM]. Decision touched: referral to special investigations. Personal information used (kinds): claim details, contact details, claim history, potentially financial and health information depending on claim type. Fully automated or human-finished: human-finished. In scope (initial view): In scope. Reasoning: although a person decides every referral, the model substantially and directly shapes which claimants are investigated using their personal information, and being referred to a fraud investigation could reasonably be expected to significantly affect a person's interests. Confidence: high. Flagged for human judgement: confirm the kinds of health and financial information used, as this varies by claim type.
The human decision gate. This is the step that cannot be delegated. The privacy lead does not accept the model's "in scope" call as the answer. She treats it as a recommendation and tests it against the source. She confirms, by reading APP 1.8 and the OAIC guidance directly, that a human-finished referral shaped by a model is exactly the third category APP 1.8 names. She checks with [TEAM] which kinds of personal information the model actually uses, because the model flagged that it was guessing on health and financial fields. She records her decision and reasoning in the register, names herself as the owner, and dates it. Only then does the system move from "model says in scope" to "in scope", and only then does it feed Prompt 3 to draft the disclosure line.
The disclosure language that results, written at the level of kinds, might read: "We use automated tools to help identify claims for further review, including potential fraud assessment. These tools use information from your claim and your claims history. A staff member makes the final decision on whether a claim is referred for investigation." That is a complete, honest APP 1.8 disclosure for this system. It explains nothing about the model's logic, names no individual, and would survive a regulator asking how it was reached, because behind it sits a dated register entry, a recorded human decision, and the OAIC test applied to the facts.
The lesson the worked example carries is the one the whole obligation turns on. The model is fast at structuring, classifying and drafting. It is not the decision-maker. Every scope call, every disclosure line, passes through a named human who has checked it against the primary source. The project and the prompts compress weeks of formatting and first-draft labour. They do not compress the judgement, and they are not allowed to.
The AI angle most teams will miss
The honest value of this obligation is not the privacy policy paragraph. It is the inventory that produces it. To write a true disclosure, you have to know where in your organisation a machine makes or shapes decisions about people. Most large organisations cannot answer that question today without a project, and the gap between what the business thinks is automated and what is actually automated is usually wide.
That inventory is the same artefact AI governance, model risk and operational resilience all depend on. A board cannot oversee AI it cannot see. A model risk function cannot govern models nobody has listed. An incident response plan cannot cover decisions nobody mapped. The December obligation drags that map into the light and attaches a regulator and a deadline to it. Treated narrowly, it produces a paragraph. Treated well, it produces the foundation every other piece of your AI governance has been waiting for.
So the practical instruction is simple. Do not run this as a privacy-policy edit due in December. Run it as the automated-decision inventory you needed anyway, with a privacy-policy disclosure as the first thing it pays for. The deadline is fixed. What you build to meet it is a choice, and the larger build is the better one.
Content disclaimer: This article is for general educational and informational purposes only. It does not constitute legal advice, regulatory guidance, or a substitute for professional compliance judgement. Regulatory obligations vary by entity type, licence, and circumstance. Always refer to primary source guidance from the OAIC, APRA, ASIC, or the relevant regulatory authority.
TheAICommand. Intelligence, At Your Command.


