
RAG, or Retrieval-Augmented Generation, is the architecture that lets an AI answer from your own documents: it retrieves the relevant chunks first, then generates an answer using them. Most enterprise AI tools in 2026 are RAG underneath.
Why this matters
If you have ever asked an AI assistant a question about your own policies, your own contracts, your own files, and got a precise answer with the right reference, you have used a Retrieval-Augmented Generation system. Most enterprise AI tools, including Microsoft 365 Copilot, custom ChatGPT and Claude integrations, and almost every "chat with your documents" product on the market, are built on this architecture.
You do not need to know the engineering. You do need to know what RAG is, when it is the right answer, and what to ask vendors who pitch it. This article does that without code.
The mental model: a research assistant in a library
Imagine you ask a research assistant a question about your organisation's leave policy. The assistant has two options.
Option one: answer from memory. They have read most things, but their memory is fuzzy and they may invent details to plug the gaps.
Option two: walk to the library, find the policy document, read the relevant section, then come back and answer your question with the document in hand.
Option two is RAG. The assistant retrieves the right pages first, then generates the answer with those pages as the source.
That is the entire idea. Everything technical below is mechanics.
How does a RAG system actually work?
A RAG system does three things every time you ask a question.
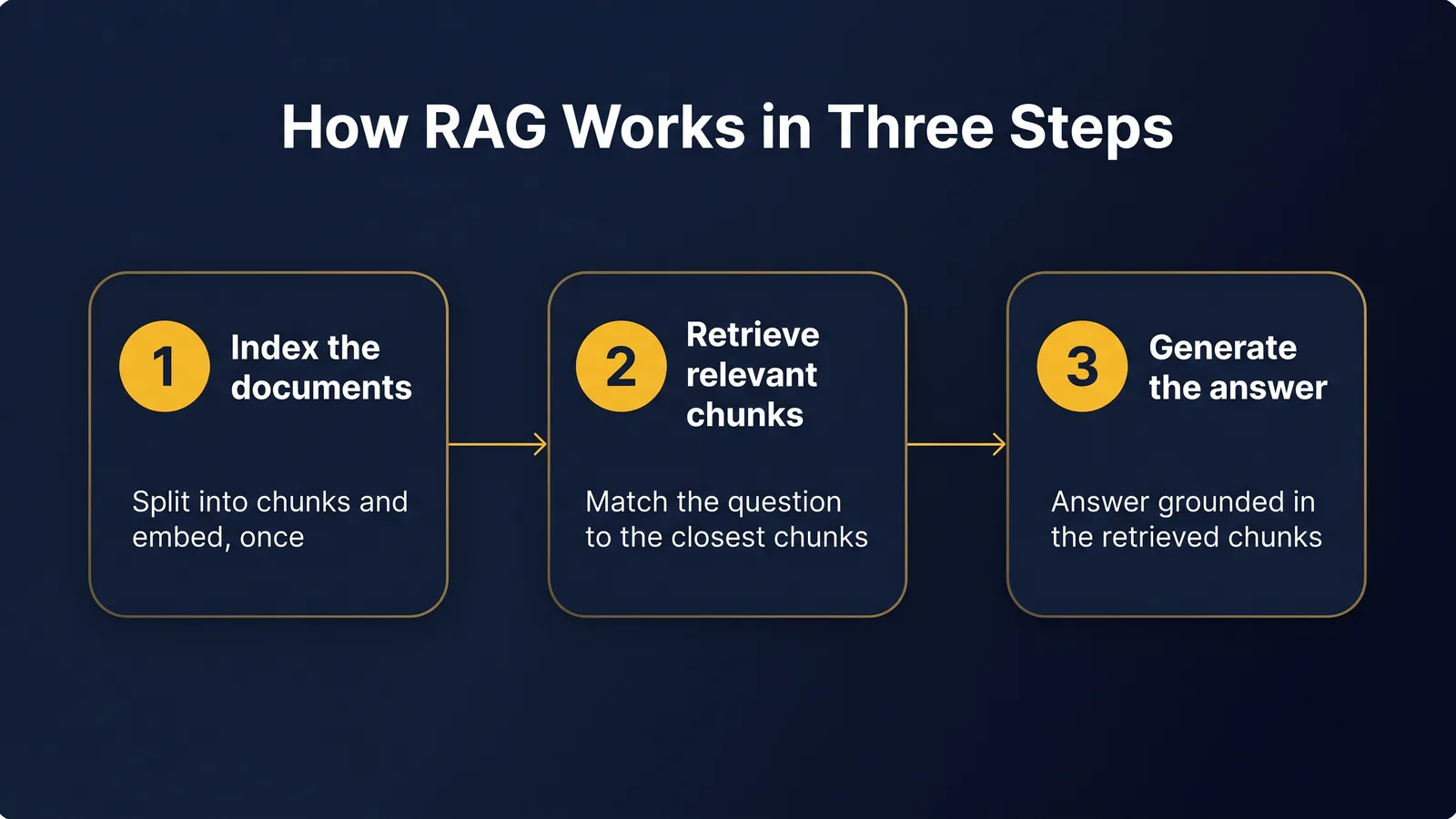
Step 1: Index the documents (once, up front)
Your documents are split into chunks (a paragraph or two each). Each chunk is converted into an embedding (a numerical representation that captures its meaning). The embeddings are stored in a vector database. This is a one-time setup, repeated when documents change.
Step 2: Retrieve the relevant chunks (every time you ask)
When you ask a question, the system converts your question into an embedding too. It then searches the vector database for the chunks whose embeddings are closest to the question's. Typically the top three to ten chunks come back.
Step 3: Generate an answer using the retrieved chunks
The chunks are pasted into a prompt with your original question, and the language model is asked to answer using only the chunks. The result is an answer grounded in your documents rather than the model's general training.
That is the RAG loop. Index once, retrieve every time, generate using the retrieved context.
When should you use RAG?
RAG fits when four things are true.
You have a defined corpus. A policy library, a knowledge base, a regulator's published guidance, your meeting transcripts. The corpus has a boundary.
The corpus changes more often than weekly. Daily policies, monthly guidance, quarterly contracts. Anything that changes infrequently can be pasted directly into a prompt or held in a Custom Project.
Answers must cite the source. Compliance, legal, regulatory, and clinical contexts almost always have this requirement. The model needs to point at the paragraph it is drawing from.
The corpus is too big to fit in a context window. A 50-page policy fits. A 5,000-page policy library does not.
If three or four of these are true, RAG is likely the right architecture. If only one or two, simpler approaches usually win.
When RAG is the wrong answer
A common mistake is to default to RAG when a smaller solution works better.
For a single document under 100 pages, paste it into Claude or ChatGPT directly. No retrieval needed. The whole document fits.
For a stable knowledge base under 500 pages, a Custom Project (Claude or ChatGPT) holds the documents in the system context. Simpler, cheaper, and often more accurate than building a vector database.
For freshness-sensitive questions, RAG over your tenant alone will miss anything that happened today. Add web search or a real-time feed.
The temptation in 2026 is to RAG everything because vendors are happy to sell it. Resist. Smaller is faster, cheaper, and easier to govern.
How do RAG systems fail?
Even a well-built RAG system has predictable failure modes. Knowing them is the difference between trusting the output and using it well.
Retrieval misses. The chunks the system pulls back may not contain the relevant answer, even if the answer is somewhere in the corpus. Causes include poor chunking, weak embeddings, ambiguous questions, and corpora where the answer to a question is spread across many documents rather than concentrated in one. The model will then generate an answer from chunks that are close but wrong, with confidence.
Stale index. If the corpus has been updated since the last embedding run, the system retrieves yesterday's policy when you needed today's. Update cadence is part of the design.
Generation drift. The model is asked to answer using the retrieved chunks. It may, despite the instruction, drift into general knowledge to fill gaps. The trustworthy systems include explicit instructions and post-hoc checks to keep the model on the chunks. The poor ones do not.
Permission leak. A user asks a question. The retrieval layer pulls back a chunk from a document the user does not have permission to see. The model answers using that chunk. The user has now received information they should not have. This is one of the most consequential RAG failure modes in regulated work, and it is entirely a permissions problem rather than an AI problem.
The mitigations are documented evaluation, regular re-indexing, careful prompt design at the generation step, and access controls that mirror your tenant's permission model.
Three questions to ask any RAG vendor
If a vendor pitches a "chat with your documents" product, ask these three questions.
1. Show me the retrieval, not just the answer
A trustworthy RAG system shows which chunks it retrieved before generating the answer. If the vendor cannot or will not show you the retrieved chunks, the system is opaque and you cannot audit it. Walk away.
2. What happens when the answer is not in the documents
A well-built RAG system says "I do not have that in your documents". A poorly built one falls back to the model's general training and gives you an answer that looks confident but is not grounded. Test this with a question you know is not in the corpus.
3. How do you handle confidential or restricted documents
RAG systems retrieve documents in response to user queries. If your tenant has documents that are restricted to certain users (HR files, board papers, client matters), the retrieval layer must respect those permissions. Ask explicitly how the system mirrors your access control model. The right answer is a long answer.
RAG is not the only retrieval pattern
Two related architectures are worth knowing because vendors use the terms interchangeably even though they are not the same thing.
Tool use (function calling). Instead of retrieving chunks of documents, the model calls structured tools. It might call a calculator, a database query, an internal API. This is more powerful than RAG when the answer needs to be computed rather than looked up. Many enterprise systems combine the two.
Web-grounded generation. The model retrieves not from your corpus but from the live web. Useful for current-events questions and freshness-sensitive lookups. Less useful for confidential internal questions because the documents that matter are not on the public web.
The right architecture for an enterprise assistant in 2026 is often a combination. RAG over the internal corpus, tool use for structured lookups, and web grounding for freshness. Vendors who build all three together produce the most useful systems.
A worked example
A GRC team wants to build an internal tool that lets risk staff ask questions about the bank's CPS 230 obligations. They have a 2,000-page library of internal policies, regulator guidance, and incident records.
Wrong approach: paste the library into a Custom Project. It will not fit, and the model will be slow and lose track of context.
Right approach: build a RAG system over the library. Each policy is chunked, embedded, and indexed. A risk officer asks "what is our incident notification timeline for a critical operational disruption". The system retrieves the three chunks most relevant to that question (CPS 230, the bank's incident response policy, the most recent regulator letter). The model generates the answer using those chunks and cites each one.
That is a reasonable RAG use case. Anything smaller than that probably does not need RAG.
Common mistakes
Treating RAG as a search engine. RAG is search plus generation. The generation step is the value. If you only need search, build search.
Skipping evaluation. A RAG system needs to be tested with real questions and real documents. Pilot with 50 questions before relying on it.
No human in the loop. RAG outputs in regulated work must be reviewed by a human. The retrieval can fail, the generation can hallucinate, and the citations can mislead. A reviewer is part of the system, not optional.
Build vs buy
A natural question once you understand RAG: should our team build a RAG system, or buy one off the shelf.
The honest answer in 2026 is buy first, build only if buy does not fit. Vendor RAG products from Microsoft, Glean, Notion, Elastic, and dozens of category-specific players have matured fast. They handle the chunking, the embeddings, the retrieval, the permission mirroring, and the audit log. Their incentive is to make the product work without engineering effort on your side.
The case for building is when your corpus has unusual structure (highly technical or domain-specific terminology, structured tables, time-sensitive data) or when your governance posture requires controls the vendors do not offer. For most working professionals reading this article, the answer is to evaluate two or three vendors in a pilot rather than build from scratch.
What RAG looks like to the user
If RAG is invisible at the surface, you are using a well-built one. Type a question, get an answer, see a citation back to the document and paragraph the answer was drawn from. The citation is the tell. A "chat with your documents" product without citations is hiding its retrieval, and is therefore harder to trust.
Citations also change how you should write prompts inside a RAG system. You can ask for the citation directly. "Answer the question and quote the exact paragraph from the source document you are relying on." The model will pull the chunk into the answer. This is more useful for review than a paraphrase.
Try this
Open Claude or ChatGPT and upload (or paste) a document of your own. Ask the same question with and without the document attached. The difference between the two answers is what RAG buys you, in miniature. Note where the answer with the document is more precise, and where the answer without it is broader.
Glossary
RAG (Retrieval-Augmented Generation). An architecture where the AI first retrieves relevant chunks of your documents and then generates an answer using both the retrieved chunks and the user's question.
Embedding. A mathematical representation of a chunk of text that lets the system find semantically similar chunks.
Vector database. A database designed to store and search embeddings quickly.
Chunk. A small piece of a document, typically a paragraph or two.
Hybrid retrieval. Combining keyword search with embedding-based search.
Where to go next
- Privacy-Safe AI for Regulated Work
- Choosing Claude, ChatGPT, Gemini or Copilot for Your Job
- Reading an AI Tool Safety Card
Bottom line
RAG lets an AI answer from your own documents by retrieving the relevant chunks first, then generating a grounded answer with a citation you can check. It is the right architecture when you have a defined corpus that changes often, answers must cite the source, and the corpus is too large for a context window. When something smaller works, use it, because smaller is faster, cheaper, and easier to govern.
Do this Monday:
- Check whether your use case has a defined corpus, frequent change, a citation requirement, and a corpus too big for a context window before reaching for RAG.
- For a single document under 100 pages or a stable base under 500 pages, paste it in or use a Custom Project instead of building a vector database.
- Ask any RAG vendor to show the retrieval, say what happens when the answer is not in the documents, and explain how they mirror your access controls.
- Pilot with 50 real questions and keep a human reviewer in the loop before relying on the output.
TheAICommand. Intelligence, At Your Command.


