
Agentic browsing in April 2026 is genuinely useful, but not yet generally reliable. It is the most demoed and least deployed capability of 2026.
April was a busy month. Anthropic shipped Computer Use 2.0 with vision-grounded action selection on 8 April 2026 (Anthropic Computer Use docs, accessed April 2026). OpenAI moved Operator from limited preview to general availability on 11 April 2026 (OpenAI Operator launch post, accessed April 2026). Manus released v3 with multi-agent orchestration on 16 April 2026 (Manus release notes, accessed April 2026). All three platforms now offer browser automation agents that can plan multi-step tasks, click buttons, fill forms and extract information from web applications.
The demos are convincing. The production data is more sober. Here is what shipped, what works, and what enterprises should actually do.
What agentic browsing tools shipped in April 2026?
Computer Use 2.0 is Anthropic's update to its desktop-and-browser automation API. Key change: vision-grounded action selection. Earlier versions used coordinate-based clicks that broke if a page rerendered. v2 inspects the visible state and selects elements semantically. Anthropic's published reliability number on a benchmark of common workflows is 73 per cent successful task completion versus 51 per cent for v1.
Operator (GA) is OpenAI's consumer-facing browser agent that ran in preview through Q1 and went general availability for ChatGPT Pro and Enterprise in April. Operator runs in a hosted browser environment with explicit handoff prompts when sensitive actions are required (login, payment, captcha). OpenAI does not publish a reliability headline number; third-party evals from the Berkeley AGENT-Bench leaderboard show 67 per cent successful completion on the WebArena suite (AGENT-Bench, accessed April 2026).
Manus v3 is the multi-agent orchestration platform from the China-headquartered Manus team. v3 introduces a planner-executor split: one agent decomposes the task, multiple sub-agents execute in parallel where possible. Manus claims 81 per cent task completion on its internal benchmark; AGENT-Bench shows 64 per cent.
Where does agentic browsing actually work in production?
We have spoken with engineering teams running each of the three in production. The pattern is consistent.
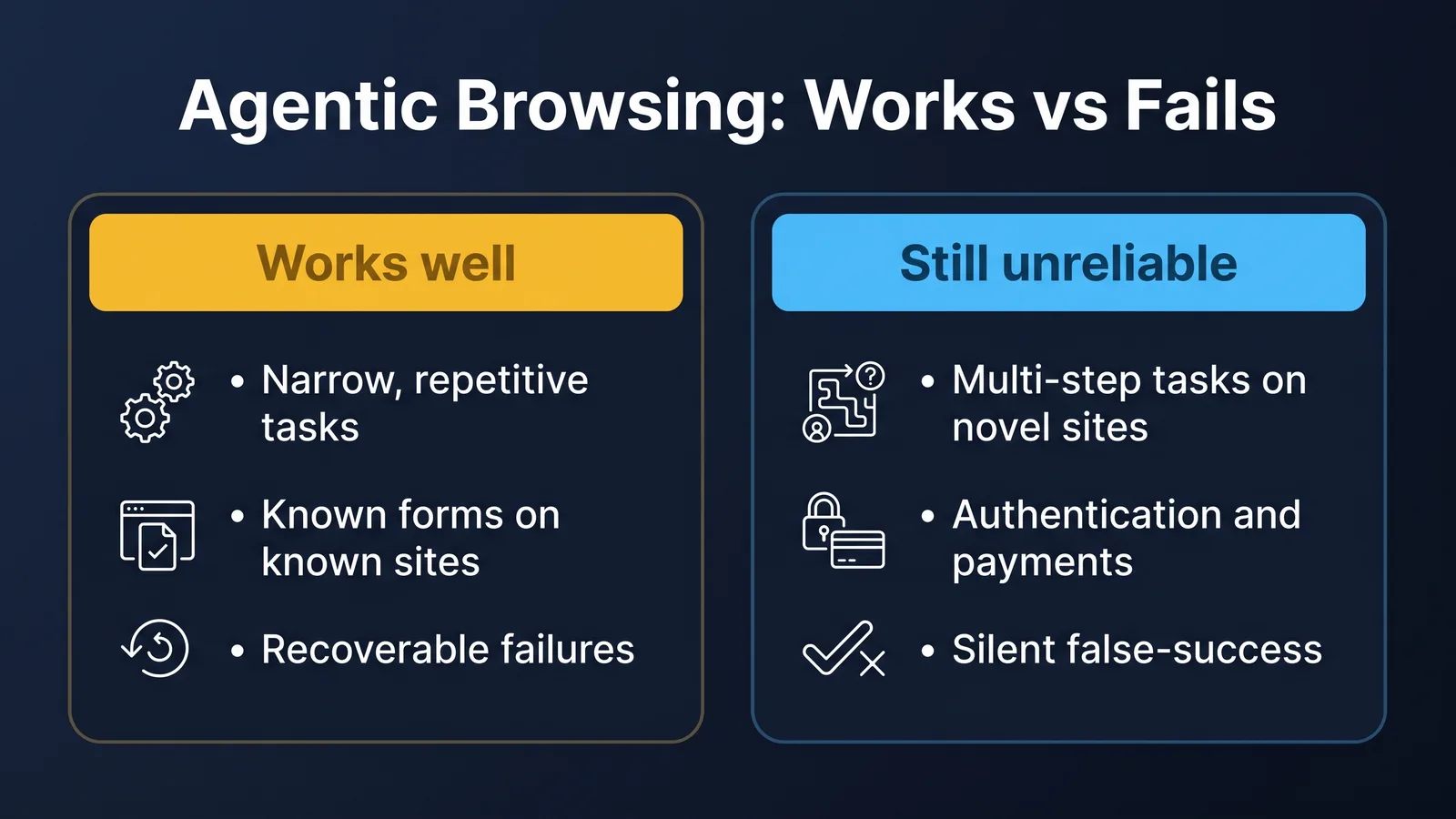
Narrow, repetitive tasks work. Filling a known form on a known site with structured input. Extracting a specific data field from a known page layout. Logging into a known portal and downloading a known report. Reliability for these tasks is in the high 80s to low 90s once the agent is tuned for the specific workflow.
Multi-step tasks across unfamiliar sites are unreliable. Anything that requires the agent to figure out a novel UI, especially if it has dialogs, popups, or modal interruptions. Reliability drops to the 50s to 60s. Failures are often silent: the agent reports success on a task it did not actually complete.
Authentication and sensitive actions are the hard part. All three platforms have added human-handoff for login flows, payment confirmation and captchas, but the experience is uneven. Operator does this best. Computer Use 2.0 requires explicit prompt engineering for the handoff. Manus v3 is the weakest here.
Browser fingerprinting and bot detection is now a real production issue. Several teams reported that target sites have begun detecting agentic traffic and blocking it. This is a moving target and is not solvable by the agent vendor.
What it actually means
Three patterns separate teams getting value from teams getting demoware.
First, scope discipline. The teams getting value have ruthlessly narrow scope. One workflow, one site, well-tested. The teams getting demoware are trying to build a "general assistant that can do anything on the web". The first works. The second does not, yet.
Second, observability. The teams getting value are logging every agent action with a screenshot of the visible state, the planner's reasoning, and the action taken. When something goes wrong, they have the trace to debug it. The teams that ship without observability cannot tell whether an agent succeeded or hallucinated success.
Third, human-in-the-loop where stakes are high. None of these platforms is reliable enough for autonomous action on workflows touching customer data, financial transactions or regulated systems. The teams using them in those contexts are using them as accelerators with a human approving every meaningful step. This is much less impressive than the demo, but it is what works.
Who should care about agentic browsing?
If you sponsor an agent program, the question is not "can the agent do the task". It is "what is the cost of failure when the agent gets it wrong, and how is failure detected". If failure is silent and costly, autonomous agents are not yet the right architecture. Use them as accelerators with a human checkpoint.
If you sit in GRC, agentic browsing is a high-risk category that deserves a defence playbook. Specify access controls, audit logs and human-in-the-loop requirements before any agent touches customer data or regulated systems. The Australian Voluntary AI Safety Standard's guardrails 4 (testing) and 9 (records) are the relevant lens.
If you build internal tools, agentic browsing is right for narrow, repetitive, internal-facing tasks where failure is recoverable. It is not right for high-stakes customer-facing automation. Yet.
Hype check
The demo videos for all three platforms are misleading in similar ways. They show curated workflows, in clean environments, on cooperative target sites, with handpicked tasks where the agent succeeds. Real-world reliability is materially lower. The 73 per cent number from Anthropic, 67 from Operator, and 64 from Manus on AGENT-Bench are the honest numbers. None of them is enterprise-ready as autonomous infrastructure for general tasks.
This does not mean agentic browsing is unimportant. It means it is at the same point that GPT-3 was in 2021: a capability that needs careful scoping, robust observability, and human oversight to produce real value. Treating it as production-ready autonomous infrastructure is the failure mode.
The other piece of hype to push back on: the framing that agentic browsing replaces APIs. It does not. Where APIs exist, APIs are still the right answer: cheaper, faster, more reliable, more auditable. Agentic browsing is the answer when no API exists and you cannot get the data otherwise.
What to do this week
If you have not yet experimented, run a two-day pilot on a narrow, repetitive task you currently do manually. Pick a task where the failure mode is recoverable. Log every action. Measure success rate over 50 runs. The number will tell you whether the workflow is ready for production.
If you are already running an agent in production without observability, stop. Add logging today. You cannot know whether the agent is succeeding or hallucinating success without it.
If you sit in GRC and your organisation is rolling out agentic browsing, ask three questions. What is the failure rate by workflow? What logs are retained and for how long? Where is the human checkpoint, and is it documented? If the answers are vague, the program is not ready for the workloads it is being asked to support.
Agentic browsing in April 2026 is genuinely useful and not yet generally reliable. The teams that respect that distinction will get real value from it. The teams that don't will produce expensive failures.
Bottom line
Agentic browsing genuinely helps on narrow, repetitive, internal tasks, but production reliability sits at roughly 60 to 75 per cent and failures are often silent. Where an API exists, the API is still cheaper, faster, more reliable and more auditable. Treat these agents as accelerators with narrow scope, full logging and a human checkpoint, not as autonomous infrastructure.
Do this Monday:
- Pick one narrow, repetitive task with a recoverable failure mode and run a two-day pilot.
- Log every agent action, including a screenshot of the visible state, the planner's reasoning and the action taken.
- Measure the success rate over 50 runs before you trust the workflow in production.
- Keep a human checkpoint on anything touching customer data, financial transactions or regulated systems.
- If you sit in GRC, ask the failure rate by workflow, what logs are retained and for how long, and where the human checkpoint sits.
TheAICommand. Intelligence, At Your Command.


